1
Steph W. from SEOPressor

👋 Hey there! Would you like to try out this New AI-Powered App that'll...
...help you check your website and tell you exactly how to rank higher?

Actionable SEO tips, tutorials, and insights to help you rank higher.
84
score %
SEO Score

Found us from search engine?
We rank high, you can too.
SEOPressor helps you to optimize your on-page SEO for higher & improved search ranking.
By vivian on November 26, 2015

Many people don’t realize that search engines don’t read websites the way humans do. While human readers can easily understand the context of a web element at a glance, search engines like Google need extra information to tell them what’s something is all about.
And what exactly are this extra information? It’s something that is called metadata, or in human speak – data about data. There are many standards (called schemas) of writing structured metadata and two of the most recognized ones as of late are Dublin Core and Schema Markup.
[bof_display_offer id=18960]
You might’ve heard about Schema Markup given how it was popularized by Google. But do you know that Dublin Core has been around for quite a while and is used and endorsed by well-established organizations?
There are some arguments about which is better for SEO so we’ll do a head to head comparison to see the advantages and advantages of each:
Dublin Core is a general-use, descriptive metadata schema inspired by the older MARC system. Dublin Core tends toward a more abstract model, which in its unqualified form, can be used for metadata sharing independent of any specific coding syntax.
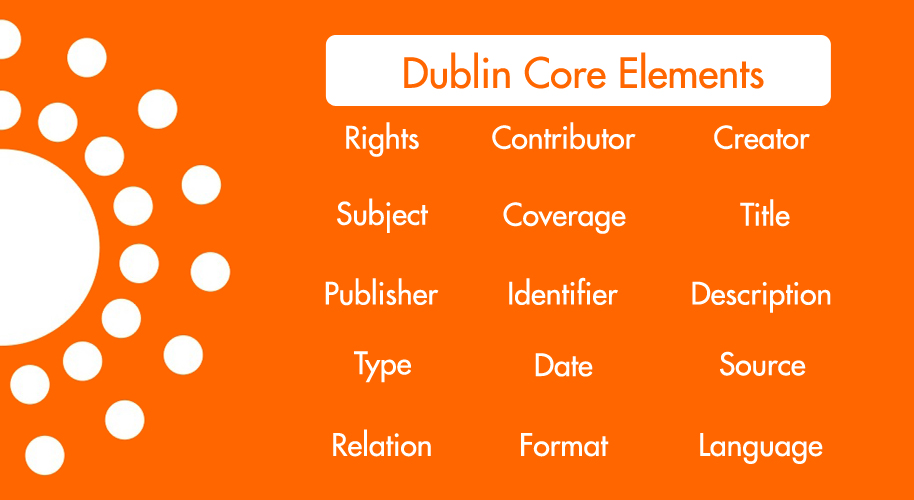
There are 15 original elements in Simple Dublin Core, all optional and repeatable. This “classic” Dublin Core Metadata Element Set has been endorsed by ISO Standard, NISO Standard, IETF RFC, and others.
Three additional elements and various refinements (qualifiers) were added to produce “Qualified Dublin Core.” Since 2012, all of the elements and refinements have been conglomerated together and renamed “DCMI Metadata Terms.” The modern version still makes use of RDF.
Schema.org provides a collection of metadata schemas that can be utilized by webmasters in marking up HTML-webpages to ensure they are understandable by today’s major search engines. These schemas can also, like Dublin Core, be used for structured interoperability purposes.
Schema.org consists of a set of microdata terms, item types, and properties. The simplicity of microdata is bolstered by increased support for combined usage of multiple metadata schemas.

Schema.org facilitates structured data mark up on webpages, which can render richer, more relevant search results. One of the main reasons for this benefit is that on-page mark-up enables major search engines to better analyze the content of generated web data.
This is rather crucial in the present online environment since a large number of modern websites are generated from offline database sources.
Direct access to this “semantic” or “intelligent” Web is one of the best features of Schema.org. Schema.org provides a common mark-up vocabulary, which eases the job of webmasters in deciding on which mark-up schemas to use.
This, in turn, leads to maximal benefits being derived from webmasters’ mark-up endeavors. Additionally, new applications and other Web tools are enabled by use of the data structure of Schema.org.
| Dublin Core: | Schema.org: |
|---|---|
| Is a descriptive metadata schema inspired by MARC | Is a collection of metadata schemas that are focused on SEO and are particularly targeted at webmasters |
| Uses a relatively abstract model | Can be used for interoperability purposes as well |
| Has many important endorsements (IETF RFC, ISO Standard, NISO Standard) | Focuses on facilitating data mark-up for richer, more relevant search results |
| Uses qualifiers known as “refinements” to increase precision | Takes full advantage of the semantic Web |
| Is now known as DCMI Metadata Terms | Allows certain new tools and applications to be used |
| Makes use of RDF |

Dublin Core originated in Dublin, OH, in 1995 at a metadata workshop co-hosted by the Online Computer Library Center (OCLC) and the National Center for Supercomputing Applications (NCSA). It was called “Core” because it was conceived as a broad-based, generic metadata schema that would be usable for a wide range of resource items and across a wide array of business purposes.
Beginning in 2000, Dublin Core worked closely with the World Wide Web Consortium (W3C) in its efforts related to RDF and soon ranked among the most popular vocabularies utilizing RDF. Dublin Core also soon joined the Linked Data Movement.
In 2008, the Dublin Core Metadata Initiative (DCMI) separated from the OCLC and steered its own course. Since the separation, DCMI has vigorously pursued increased semantic interoperability.
DCMI occasionally updates Dublin Core’s semantics whenever a consensus has been reached among its members. Shared metadata innovations, promotion of best metadata practices, and cooperation at international metadata workshops are all among DCMI’s activities.
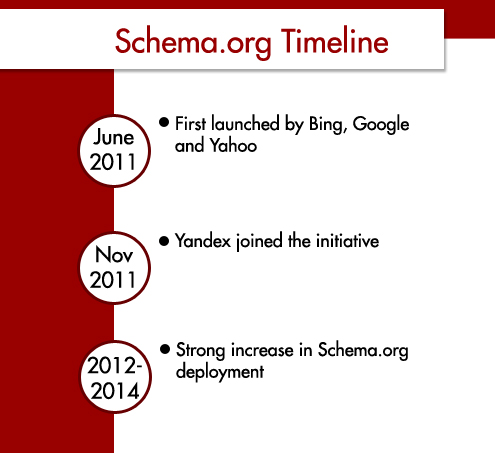
On June 2nd, 2011, Google, Yahoo!, and Bing launched a new metadata initiative specifically targeting optimal search engine results and display. The aim was to create a metadata schema optimally usable by webmasters, much in the spirit of sitemaps.org.
In November of that same year, Yandex, the largest Russian search engine, joined in the effort. Thus, the largest search engines in the world, at the time, consolidated their efforts to provide the best possible SEO-friendly set of metadata schemas.
Much of the vocabulary was inspired by predecessors like MicroFormats, FOAF, and GoodRelations. At first, the quantity of available formats was sparse, but Schema.org has grown in schema number as well as in popularity.
A built-in extension method has allowed the seamless addition of many new properties, and the goal is to soon add many more.
Schema.org facilitates the marking up of website content by means of self-descriptive metadata information. Microdata and Ontology in HTML5 are utilized, which is recognizable by parsers and “web spiders.”
| Dublin Core: | Schema.org: |
|---|---|
| Originated at an OCLC & NCSA workshop in Dublin, OH, in 1995 | Is very young, only having been founded in 2011 |
| Was purposefully made broad-based | Was the brainchild of major search engine providers |
| Gained close connections with W3C and RDF | Began with a small number of schemas but is continuing to expand in that regard |
| Is now managed by DCMI | Is growing by leaps and bounds in popularity |
| Puts a high value on interoperability | |
| Is periodically updated through international workshops |
Dublin Core is used across both computer domains and human languages. It is not limited by business type or model. Thus, its original purposes were certainly achieved. One of the challenges of using Dublin Core is that the vocabulary is relatively restricted and the cataloging rules are not very detailed.
This problem is remedied, however, by various qualifiers that narrow the meaning and increase the semantic precision of the elements. For example, value encoding schemes may specify that a value is a controlled vocabulary item or that it uses a standardized formatting system.
Web resources commonly described by Dublin Core include: video clips, images, text, webpages, and physical objects like artwork, manuscripts, books, and CDs. In fact, each value in Dublin Core corresponds to a physical, digital, or conceptual entity of some kind. For this reason, it is often preferred for use with physical collections.
Nonetheless, Dublin Core is extremely broad in usability and is interoperable with Linked Data Cloud and the “semantic Web.” It has many endorsements, including that of W3C. Important applications using Dublin Core include OMF Open Source Metadata Framework, Zope CMF metadata products, and the EPUB e-book format. Finally, Dublin Core is also used very effectively with social media, such as Facebook Open Graph.
After exponential growth between 2012 and 2014, Schema.org metadata schemas are prevalent all over the Web. SEO performance is, unsurprisingly, the hallmark of a schema initiated by search engines and continually supported by the same parties.
Schema.org is particularly good at displaying database-generated websites properly and at treating appropriately each data type, such as thumbnails, logos, and product descriptions. Website elements are tagged quickly, easily, and accurately.
| Dublin Core: | Schema.org: |
|---|---|
| Is used across many domains, languages, and business models | Is now prevalent Web-wide |
| Relies heavily on its qualifiers to extend its vocabulary | Is the number one choice for SEO |
| Is particularly favored for descriptions of physical collections | Excels with generated websites |
| Is interoperable with Linked Data Cloud and the semantic Web | Excels at treating each data type appropriately |
| Is often trusted because it is well established and has many endorsements | |
| Is used by many notable applications and is especially effective with social media |
Though conceived from the beginning as a more general metadata schema and hailing from a more open initiative, Dublin Core is not the favorite of the largest, present-day search engines. That being said, it nevertheless can be used adequately for SEO.
As Web history continues to unfold, many “forecasters” expect Dublin Core to update to newer metadata schema and join the open data movement. It may well be that Dublin Core will morph into a more limited role as search-engine-favored Schema.org advances.
It is not clear that Dublin Core is “on its way out,” but a “division of labor” between these two metadata systems may lie in the future.
Schema.org continues to improve its SEO capabilities, and it does not seem likely anyone will catch them on that score in the near future. With the promised support of the major search engines and new schemas being added periodically, the future looks bright for Schema.org.
The use of Schema.org’s metadata structures eliminates the need for multiple, trade-off-based mark-up schemes. This alone betokens rapid future growth for this relatively new metadata provider.
Also to be noted is that Schema.org to RDF term-mapping is available and that data-entry validity can be easily tested by the Google Structured Data Testing Tool, the Bing Markup Validator, or the Yandex Microformat Validator. This ensures accurate entry and convertibility, both of which speak in favor of Schema.org remaining a major player in the metadata industry for years to come.
| Dublin Core: | Schema.org: |
|---|---|
| Will likely see a continuation of its use in many arenas | Is ever-improving and likely to become even better at SEO |
| May see a lessening of its usage for SEO | Is likely to dominate in the SEO field for a long time to come |
| Will likely include new metadata schema and the open data movement | Can be easily tested for data validity and term-mapped to RDF, and this accuracy and convertibility bode well for its future |
Although Dublin Core is older, more well established, and has a wider scope of usage at present, Schema.org is edging Dublin Core out on the SEO front. The reason for this lies in its being solely and specifically created for SEO purposes by actual search engine operators.
But that’s not to say that Dublin Core should be brushed aside that easily. A lot of business especially those that rely on interoperability with physical documents can benefit from Dublin Core. These include libraries, universities, or even document-heavy fields such as law.
And actually, who said you can’t use both? I know it can take a lot of effort to implement both of them manually. That’s why SEOPressor Connect has a built-in Dublin Core and Schema.org builder that lets you mark your content effortlessly.
You don’t even need to do the markup yourself. The builder lets you choose the metadata type you’d like to tag your content with. You can then fill up the rest of the details (headlines, description, author name, etc) in a simple form and the builder will generate and apply the markup without needing you to write even a single piece of code.
Incorporating Dublin Core and Schema.org markup on your website has never been easier!
The whole point of structuring your data has always been to communicate better with search engines like Google.
Because when Google understands entities on a deeper level, it serves better results to searchers. And now more important than ever in the SEO world is building relevance.
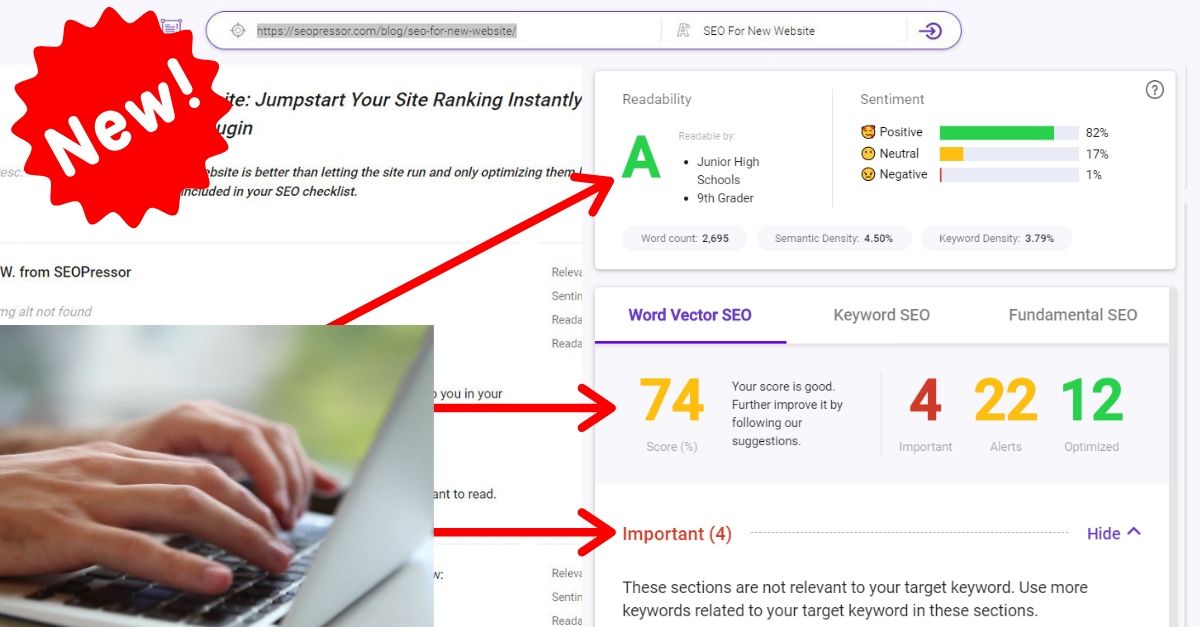
One key aspect is to take into consideration your content’s WordVector and compare it to the existing Top-ranking content to determine if it fits the contextual relevance.
Something that can help you analyze this is BiQ’s Content Intelligence, it is the only available tool that is powered by AI to handle WordVector SEO.

It analyzes your whole content to show you which section you need to edit to make your content much more relevant.
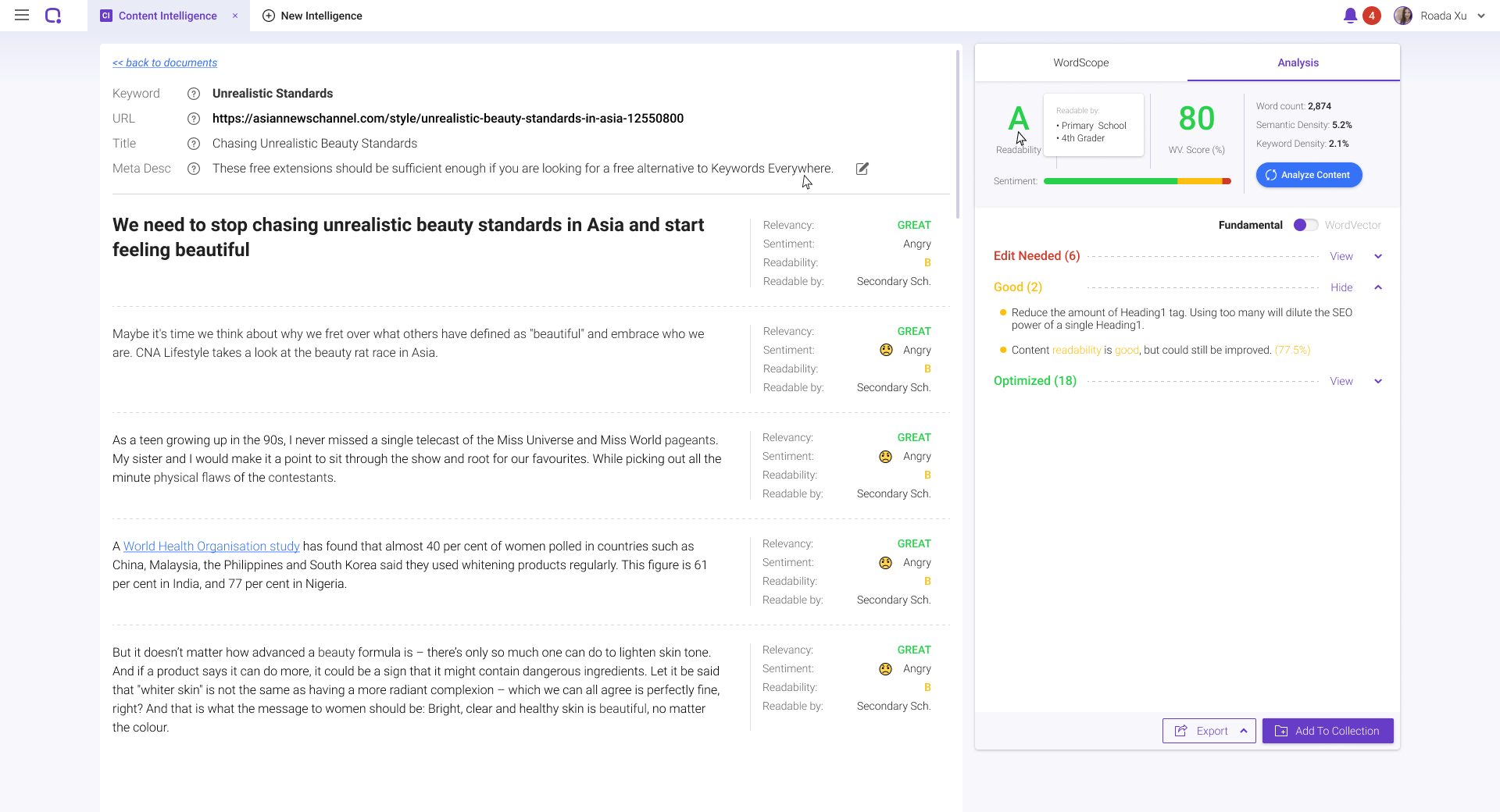
Start with revising those content that needs revisions to improve its relevancy to your target keyword.
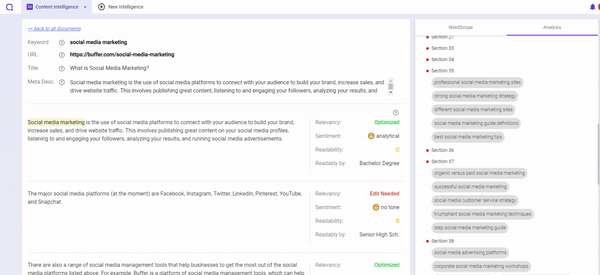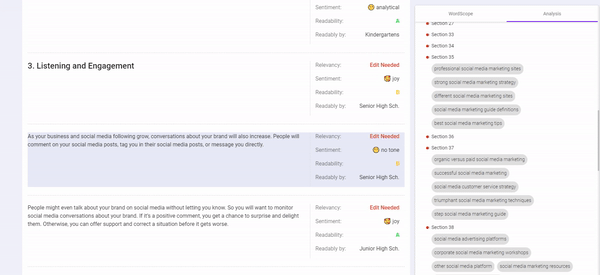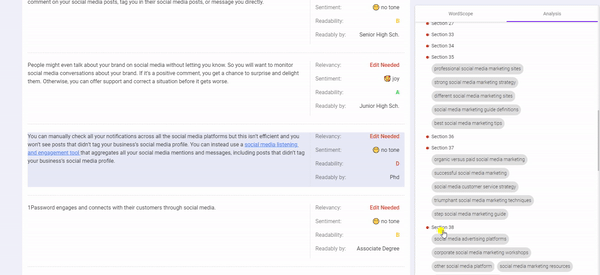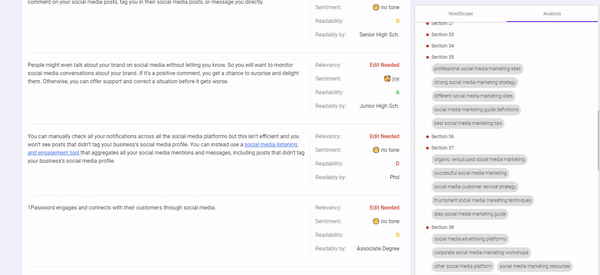
This can be really helpful especially with the ongoing trend of creating long-form content and we want to make sure we do not stray off-topic.
After all, Google is not just simply identifying and discovering information anymore, it is connecting and relating them to each other. So this is definitely something you want to look into aside from Dublin Core and Schema.org.
Sign up for free tier access to BiQ, and start analyzing your content relevance today!
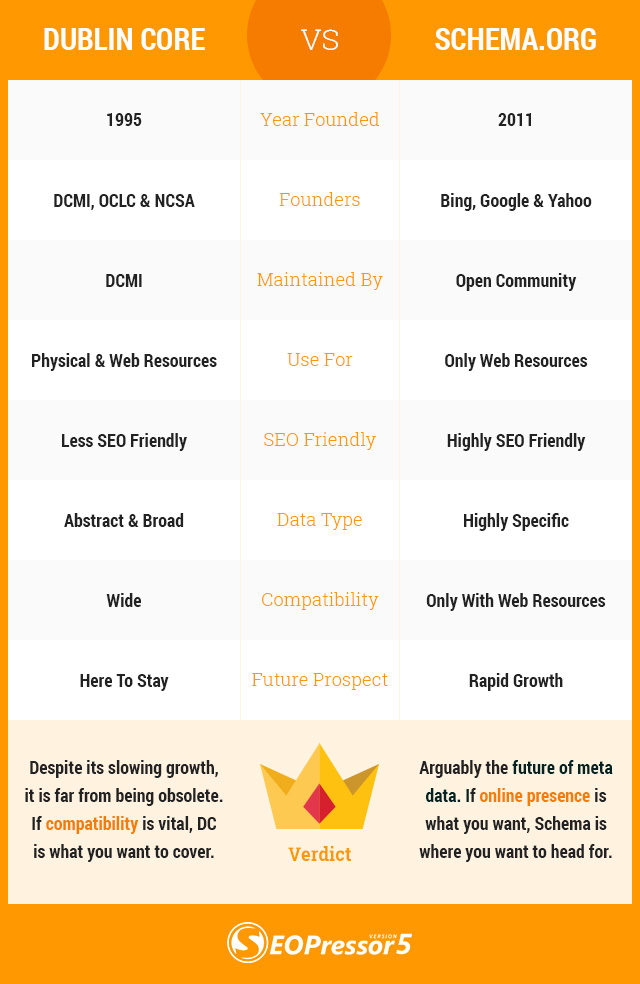
To recap and wrap things up, here is an infographic to summarize the key differences between Dublin Core and Schema.org for easy reference. You can also share your preferred choice of markup in the comment section.
Updated: 20 July 2026

Subscribe and receive exclusive insider tips and tricks on SEO.
Delivered to you right from the industry’s best SEO team.
Copyright © 2026 SEOPressor. All Rights Reserved.
Powered by Semantics BigData Analytics (SBDA).

{kind=link}