1
Steph W. from SEOPressor

👋 Hey there! Would you like to try out this New AI-Powered App that'll...
...help you check your website and tell you exactly how to rank higher?
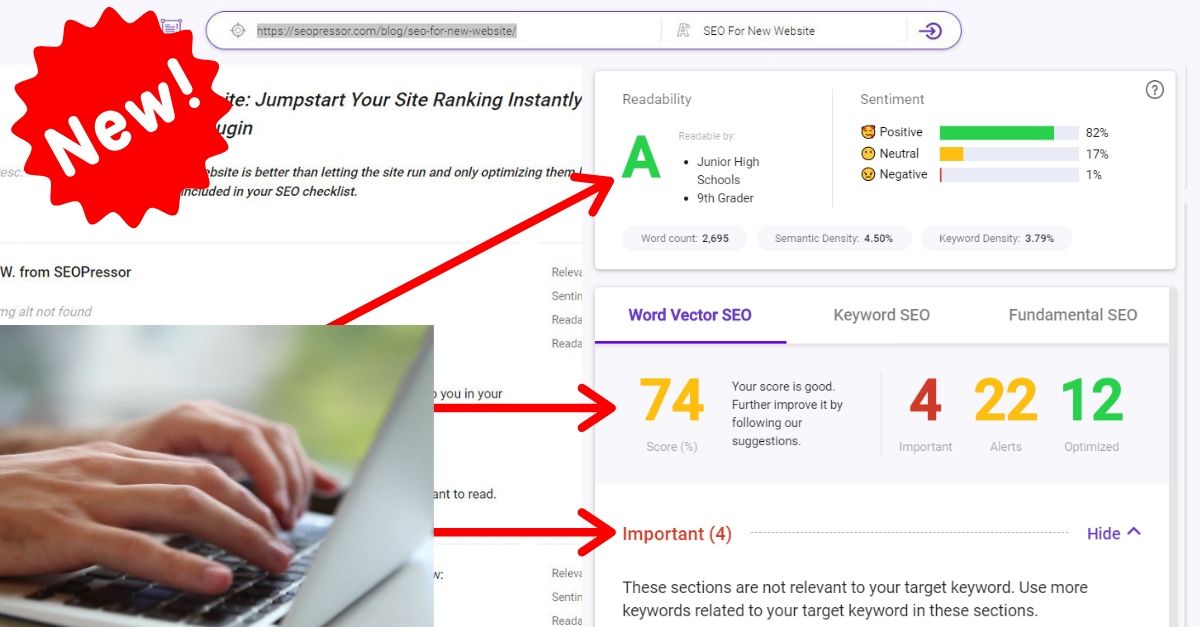

93
score %
SEO Score

Found us from search engine?
We rank high, you can too.
SEOPressor helps you to optimize your on-page SEO for higher & improved search ranking.
By jiathong on June 8, 2018

”To organize the world’s information and make it universally accessible and useful.”
That is the goal of Google as a company. Despite their venture into other technology. From producing smartphones to being the major digital advertisement provider. Google’s root stems from search, while search stems from data and user intent.
96% of Google’s income comes from ads. Around 70% from Adwords and the rest from Adsense. Google took advantage of their position as a search engine and offer advertisement spots following their intricate algorithm.
This is possible because of their huge reach of audience and subsequently the data they can collect.
Now, how does search works?
It starts from crawling to rendering those that needs rendering, then indexing. When a user tapped enter for a query, the multitudes of algorithms powered by a vast number of machines process and filter their library of indexed data to present the user with a list. A list of what they deemed the user wants.
Google is now equivalent to the verb search. Do you say “let me look that up” or do you say ”let me Google that” or perhaps you say “hey Google what is…” ? You and I and them, we all relied on Google when we want information, when we need an answer.
Fortunately, (or unfortunately for Google) there are still countries out there where Google is not the preferred search engine giant. You have Baidu in China Mainland where Google tried to set their foot in and later backtracked. Or Yandex in Russia which is the fifth largest search engine in the world. While Naver and Daum dominate the Korean internet.

Despite the dominance of Google there are still some search engines that are preferred in their home country. Like Yandex for Russia.
Despite the little setbacks in localization Google still has their iron grip in a lot of countries.
Why does that concern us? Well, that concerns every user of the internet because it means Google has access to millions and billions of data. From all around the world in multiple languages and different topics.
Google is building a massive and perhaps the biggest virtual library. They achieve that by actively curating contents all around the world wide web. They are actively getting their hands on more contents and more contents processing technologies.
They don’t only want to collect contents and data they are also trying to make sense of it. That’s why they acquired semantic search company like Metaweb, Natural Language Processing technology company Wavii. They are also tracking user behaviors on platforms like Gmail, YouTube, even your search history to your browsing behavior.
They collect data like dragons collect gems. Why does Google need those data for? Why do dragons collect gems for? Perhaps greed, yes, it may be greed. But they are doing it in the name of understanding user intent.

Google collect data like a dragon collect gems.
Millions of pieces of data that is connected to every single keyword people frequently search are used to decipher the intent behind a query, based on their access to the large pool of readily available contents.
The data pool serves as a base for their Search service, not forgetting ads, and who knows what’s more they’re using the data for? They’re just not telling you explicitly.
All of these are done to help them better analyze and pinpoint user intent. Google wants to know what exactly it is that users want. Then serve it to them on a silver plate the moment a query is made on Google search. They want to please the users. Happy users, happier Google.
Are you aware that Google signed a contract with Pentagon for Project Maven? The IT giant is assisting the weaponization of a drone by providing them the technology for machine self-learning image identification.
Do you see how cutting-edge Google’s AI technology is that even Pentagon is enlisting them help?
Now, how does it concerns search? You see, as I have mentioned before, search deals with two things. Data and human intent. In order to understand data the way that matches the human intent, the machines need to mimic the human thought process.
And one thing that machines have a hard time understanding is the complexity and sublimity of language.
The Hummingbird update released back in 2013, which was the biggest update for the search engine since 2001, created a major revamp on how search works. By utilizing and incorporating semantics theory in their algorithms, they opened a new path to the world of search.
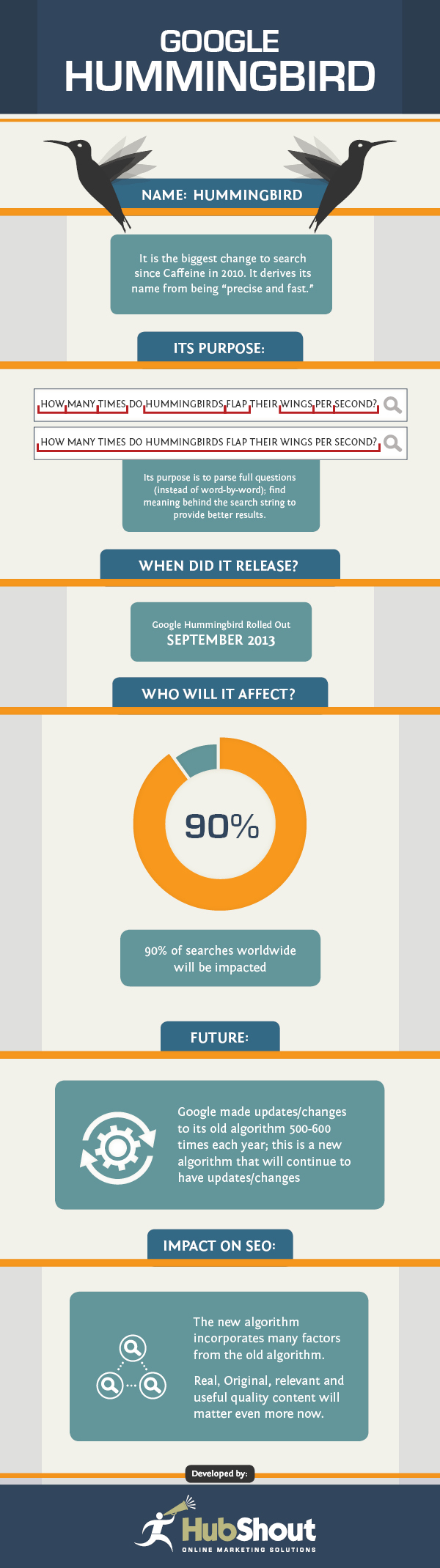
Google Hummingbird update in a glance.
This new path leads to Google understanding user intent much more fluently. Search is now one more step closer to asking Google a question instead of inputting keywords that you wish will give you the result you want.
While knowledge graph has been in the game for a bit longer than the Hummingbird update, it seems like the understanding of actually WHAT knowledge graph is had always been a little muddy.
It can be the little knowledge graph card that appears as a Search Engine Result Page (SERP) dynamic features on the right. It gives users a quick summary of the searched term. The information used for a knowledge graph card is usually pulled from multiple uncredited sources.
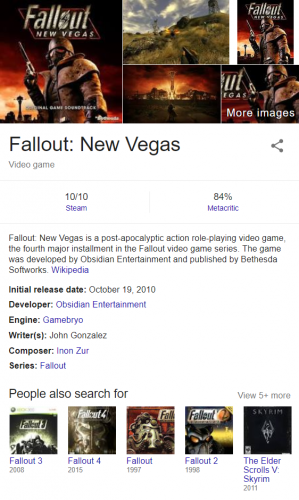
A Google Knowledge Graph Card gives users instant answer without needing to leave the result page.
But knowledge graph can also be a pool of data. It is essentially a database that collects millions of pieces of data about keywords people frequently search for on the World Wide Web and the intent behind those keywords, based on the already available content.
Google always stresses on user experience and looks for ways to help build what they think will be beneficial to the users. From pushing the AMP project for a faster mobile browsing experience to the better ads standard where non-intrusive ads are celebrated.
How can they make sure that they are serving the users right? By getting more data and making sure they’re analyzing the data right.
Knowledge graph “… taps into the collective intelligence of the web and understand the world a bit more like people do.”
Knowledge graph is Google’s database while the Hummingbird algorithm is the brain trying to make sense out of it.
“Wherever we can get our hands on structured data, we add it,” Singhal said, from an interview with Search Engine Land about knowledge graph.

Search used to work based on keywords and the literal meaning of keywords. A string of words doesn’t mean as it does for human and the machines. Human draws a relationship between the words and forms a complete meaning naturally. While machine draws out the literal meaning of each individual words without the relation process.
That’s not how we as human works.
Human mind subconsciously stores information which later acts as clues to a new piece of information to tie them into a relationship. We’re constantly putting together puzzle pieces to build a bigger picture. THAT is what Google wants to mimic.
Data collected and indexed are the information while tracked human behavior helps build context behind a query and finally, the algorithm is the webs trying to link them all together using a hint which is the word typed into the query box to make sense of user intent and give them what Google deems most fitting.
Google thirst for data because it’s the source of their knowledge. The only way to better serve the users is to understand them. Understand them as close as to how human understands each other.
Semantics search introduced a new way of data analyzing. Which involves semantics theory and most likely uses a semantic knowledge model.
What is a semantic knowledge model? Simply put, a semantic knowledge model describes what each data means and see where it fits among others. Therefore helping to pinpoint a relationship among different pieces of data.
The pieces of data are called entities. An entity is a thing, be it physical or conceptual. Each entity has attributes and characteristics which are then matched and related to those of other entities to make sense of their relationship.
This is required because most words contain multiple meaning which all mean different things when inserted into a different set of words depending on the context.
Like how human naturally makes sense of a set of words grouped together, the semantic knowledge model helps the search engine makes sense, in a human perceived way, of a set of words typed into the search bar.
The model is also used when Google tries to decide which content to pull from their library to return a search query.
In fact, other than a “normal” indexed database, Google has a separate database that is called related entities index database.
An entity is not simply a word or a thing anymore. An entity is understood and defined by its range of characteristics and attributes. More inclined to how a human perceives a word as opposed of how a thesaurus would.
“You shall know a word by the company it keeps.” (Firth, J. R. 1957:11)
Let’s look at it this way, an entity is when a word is understood including the common sense that surrounds it.
A cheery is a fruit, it’s sweet, it has a seed. These are all basic information that both computer and human knows. But one thing that the computer might not know but the human will know is the story where George Washington chopped down a cherry tree (or not, apparently it’s a myth).
Human process information in a much complex way compared to machines.
And that’s what sets a good search engine from just a search engine apart. The ability to understand a word as a complex entity instead of just its dictionary definition.
Suddenly how a content can manage to rank when the keyword is mentioned minimally, or the text is actually long and tedious to read, and not much pictures are sprinkled in makes sense.
On page optimization can only do so much when that is not what Google is primary looking at anymore.
Other than the widely known keyword density and backlinks, related entities are now another factor to consider.
Which means optimizing Latent Semantic Indexing (LSI) keywords is now more relevant than ever.
LSI keywords in the sense of information retrieval utilize Latent Semantic Analysis (LSA) to produce a set of themes, or in this case a set of keywords, that matches the document by analyzing the words mentioned. The result is a set of conceptually similar keywords.
The distributional hypothesis assumes that a set of LSI keywords will appear naturally in a document or across multiple similar themed documents. These keywords or entities are one of the factors that Google possibly used to determine whether a content is relevant or not.
Google confirms that they track related entities across the web with the existence of a related entities database. Which means pages of contents across the web is now also linked with related entities.
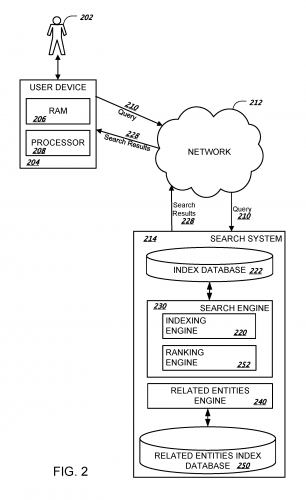
Google has both an index database and related entities index database.
What content creators and content marketers can take away from this is: keep your friends close and your enemies closer.
When you’re thinking about a topic to extend on, look at what your competitors have written. Cause they will be your related entities. The contents that they have poured out is a part of what Google makes of the topic.
Now is also time for you to take search intent seriously. Google has pools of data and multiple ways they can use to track user behavior to come up with what user really wants. We should do the same.
“Additionally, questions that users will likely have about an entity after submitting a query directed to the entity can be predicted and information about entities that are answers to those questions can be provided to the user as part of a response to the query…”
Webmasters and content writers alike are worried that with the SERP features popping up aiming to provide users with instant answers, their click-through rate will suffer.
Well according to HubSpot, the contents showcased in featured snippet which occupies rank zero actually has around double the click-through rate compared to the normal blue links results.
People are concerned that one day Google will be self-sufficient with their knowledge graph and content creators are no longer needed.
Well, I think unless the day a machine can articulate their own original opinion on a topic instead of act as a curator of information, content writers will not die out.
Why? Let’s take another look at Google’s mission.
They want “organized information that is useful and accessible”
Is Google organizing information? Only when the creator gives them clue on what a piece of content is.
Can Google generate information without any human input? No.
Who is the one who deems something useful or not? Human.
How can information be accessible? On digital networks created by human.
Technology is born from the collected wisdom of human aimed as a tool to serve humans. They are the middleman of information transmission from one human to another. So no, Google will not take over the world. Not in the sense of content creation anyways.
Let’s plan out a strategy using Google’s mission as a guideline.
1. Make sure that your website appears organized to both crawlers and users

Structured data is what helps Google identify the entities present in your content.
Try to use metadata and markups wherever you can to communicate with the crawlers and indexers.
Readers might immediately understand that Homer Simpsons is a name. But without proper markup, the search engine will not get it.
Schema acts like a tag to tell the search engine which part of your content means what.
It’s a standard and widely used form of microdata born out of a collaborative effort between Google, Yahoo, Bing, and Yandex. When you see all these big names lined up it means you better pay them some attention.
There is an extensive list of item types that you can use. Below are some useful and more general markups that may be of use to you (just so you don’t need to go through the library yourself).
Do you have additional information about it?
What kind of content is this?
What is the first factor that makes you decide to stay, read the article or leave the page altogether?
Well for me it’s how easy to read it is. Blocks of text can be slightly intimidating and boring. While too many pictures can be distracting. If there is a huge block of ads following me whenever I scroll down the page I usually just give up.
Be organized not only for the machine but for the readers too. Make sure you structure your contents clearly and in an expected manner.
2. Create usel contents that answer to search intent
I think useful should be stated more specifically as useful for the users. In content creators words, the piece of content should match the search intent.
There are a few ways to achieve this. First and foremost, the golden rule of SEO is – do your keyword research.
I know I just stressed the importance of entities but don’t get confused cause a keyword is an entity too.
Find out what your targeted users are searching for. What troubles them? What excites them? What kind of information do they want to find out? In order to do that, you need to collect data.
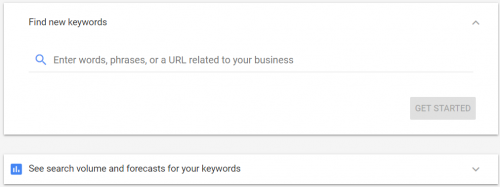
It will show you the search volume of your targeted keywords and also forecast how it will perform. All of those data come from, of course, yours truly, Google.
This fremium tool can be a good place for your long tail keyword ideas. Although it lacks the search volume feature, the different site it targets like Google, Youtube and Bing gives you a bigger variety of keyword candidates.
This LSI keyword tool gives you a list of thematically related keywords to your targeted keyword. See how much you can hit or use it as a guide to see how relevant your piece is in the eyes of a machine.
You can gauge your content’s performance by looking at the user experience data.
Is the bounce rate too high? Or maybe the time on page is too short. All of that can help you build a picture of how relevant a topic is for the users.
Google Analytics is a simple place to start.
Make revisions to your pieces if they have the potential but the data just doesn’t match up.
People nowadays want everything fast, fast cars, fast internet speed, fast information.
That’s why during the creation process strive to be able to present the most information in the most direct way. Google loves how-tos and lists. You can often see those being placed as a featured snippet.
Of course, there are those at the other end of the spectrum too. There are people who would read through lengthy pieces. That kind of people wants in-depth information.
Give your audience a healthy sprinkle of both.
3.Make sure your website is accessible to crawlers and users alike
Accessible comes in many ways and forms. In the load speed of your page to how many shares you have.
Accessible doesn’t just mean putting something up on the internet and hope that people will see it.
Machines need to pick it up before they can act as a bridge between you and the readers.
In the case of SEO, the first thing you need to do is give access to the crawlers. Then, of course, make sure they can actually interpret your HTML to make sense of your content.
To allow access to all crawlers sitewide:
User-agent: *
Disallow:
The default value to allow indexing and access to links within a page should be:
META NAME= “ROBOTS” CONTENT=”INDEX, FOLLOW”
For JavaScript websites, rendering can be a problem.
If your website is powered by JavaScript the search engine might take longer to index your page. Even though Google confirms that they have the ability to render pages themselves to properly index the JavaScript, it is not perfect.
Google recommends webmasters to implement hybrid rendering and dynamic rendering to ease the indexing process. However, it is not required.
Considering the resources needed to handle rendering, you might need to double consider before implementing any.
But using JavaScript powered website can actually raise accessibility to the users due to the service worker function and the fact that everything is dynamically fetched.
Faster load speed makes your content more accessible.
Not everyone has their internet connection via an optic fiber. 3G is still very much used and useful enough in for a big portion of the population. Which is why having a bloated website is not gonna add points to your accessibility.
Bloated HTML can also slow down your website making it more difficult to actually receive what you have to offer.
See how your load speed performs using the Google PageSpeed Insights.
Spread your contents across multiple sites.
Google search doesn’t need to be the only place people can stumble upon your content. You can take the initiative to share your content across multiple platforms.
Guest posting on other websites of your same niche can be often time helpful. For one you can reach a different audience, it also establishes your brand name. Remember the related entities we talked about? Being mentioned on another website, even without a link back to you, can be helpful in leveraging your relevance in the niche.
There are people who like pictures more than words and vice versa. Why sacrifice your outreach to both types of audiences by being only one? Convert your content into multiple formats.
You can create a stack of slideshows out of your content and share it on websites like slideshare.com and get double the outreach. Or create an infographic based on your study, that way the image itself may be able to rank higher in Google image compared to your block of text.
Quora is an awesome place to get some exposure and establish authority. See a question where your last blog post is a perfect answer? Answer the question by lifting points off your text accompanied by a link to your page.
Be creative and take the initiative to make your content shareable.
Updated: 12 July 2026

Struggling with internal linking?
Wish you could...

Automate internal linking
Use optimized anchor text
Fix 18 issues like orphan pages
Get link reporting and analytics


Save thousands of dollars (it’s 100x cheaper)
Zero risk of Google penalty (it’s Google-approved)
Boost your rankings (proven by case studies)
Rank High With This Link Strategy
Precise, Simplified, Fast Internal Linking.

Subscribe and receive exclusive insider tips and tricks on SEO.
Delivered to you right from the industry’s best SEO team.
Copyright © 2026 SEOPressor. All Rights Reserved.
Powered by Semantics BigData Analytics (SBDA).


{kind=link}