1
Steph W. from SEOPressor

👋 Hey there! Would you like to try out this New AI-Powered App that'll...
...help you check your website and tell you exactly how to rank higher?
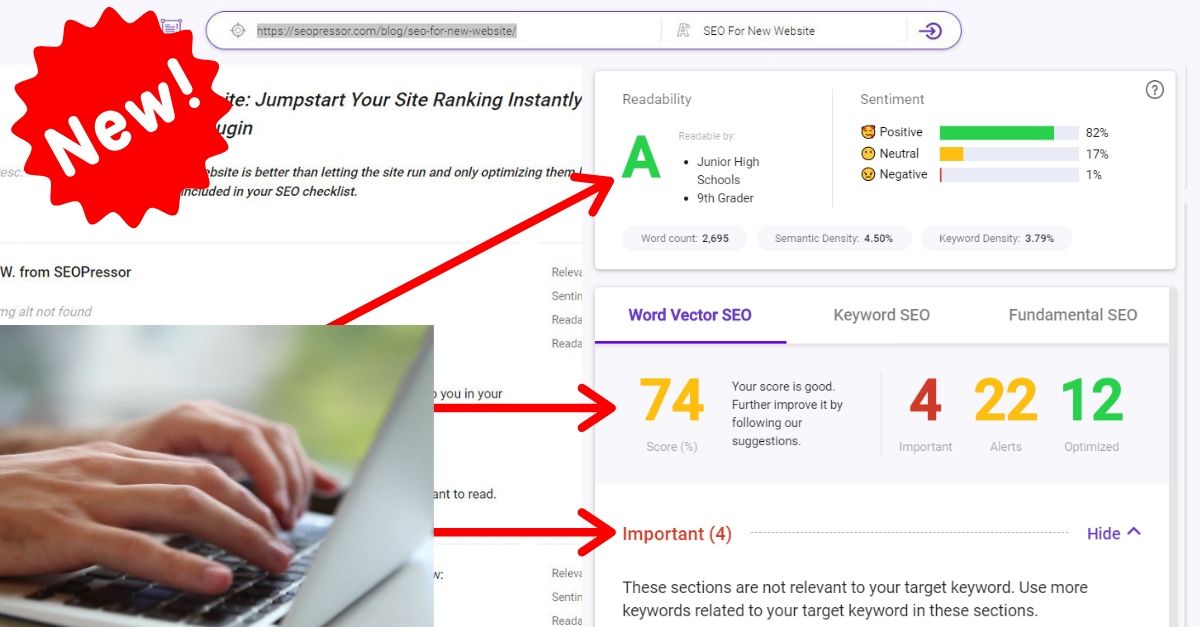

74
score %
SEO Score

Found us from search engine?
We rank high, you can too.
SEOPressor helps you to optimize your on-page SEO for higher & improved search ranking.
By vivian on April 14, 2016

As the predominance of Google shows, the Internet – more specifically, the World Wide Web – is dominated by the presence and use of web crawlers. Specifically, these are the programs that search, index and rate the various websites that exist. In short, they tell us where to go when we search for a particular word or phrase.
Still, most people have no idea how they accomplish this goal. Here is a comprehensive guide on web crawlers and how to control them through robots.txt file, meta robot tags, and with our plugin – SEOPressor Connect:

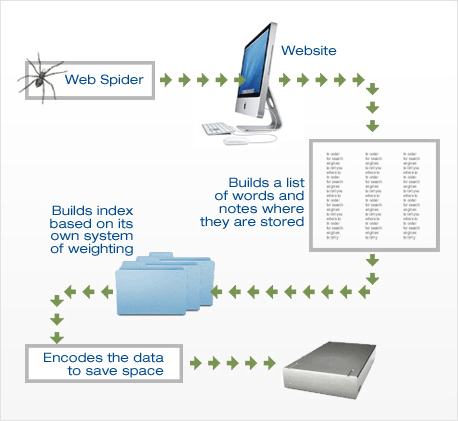
Web crawlers are known by a variety of names – industry jargon labels them spiders or bots but technically they are referred to as web crawlers.
No matter the name, they are used to scan the web “reading” everything they find. Specifically, they index what words are used on a website and in what context. The index produced is basically an enormous list, Then when a “search” is made, the search checks the pre-made index and delivers the most relevant results – that is, the results at the top of the list.
From the earliest days, search engines such as Lycos, Alta Vista, Yahoo! all the way up to the more recent ones of Bing and Google have essentially used web crawlers to define their existence.
In short, web crawlers are their sole raison d’etre. Innumerable bots are used to survey every site on the web – a Herculean task, to say the least – but one that is nevertheless incredibly lucrative. Just ask Mr. Page or Mr. Brin. Still, there is nothing to stop you from using their technology to your advantage.
In an ideal world, the owner of a website page could specify the exact keywords and concepts under which the page will be indexed. This fact, of course, has been seriously corrupted by unscrupulous SEO purveyors that want to try to game the system. Innumerable sites have populated their pages with phrases such as “Gangnam Style”, “Mila Kunis,” and “Hilary Clinton” to simply increase their web traffic.
For better or worse, this tactic is a now a way of life for the average “black hat” website promoter. A word of warning – stay away from them.
The first assault on a website is always by a web crawler. In its simplest form, it merely catalogs everything on a site. Legitimate companies being “scanned” are aware of this and would like to provide as much information as possible. The goal is to provide access to as many pages as possible and thereby establish the worth of the site. By methodically going from link to link, the bots will systematically categorize a site to the benefits of all. Still, it is the obligation of the website owner or his designated agent to make the best of this automated categorization.
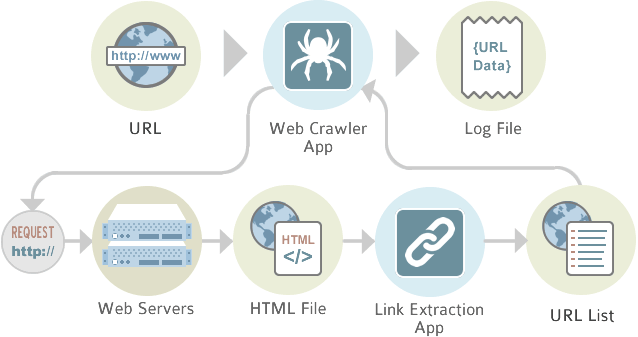
The first step in the process is to deploy a web crawler to thoroughly search a site. An index of words is thus created. Importance in this process is the use of meta tags. With these “tags”, the programmer of the site can delineate the most important keywords, phrases and concepts fro the web crawler and thus get indexed in the most appropriate way. There are also situations where a page owner does not want the page indexed and a robot exclusion protocol can be included to divert the bots completely away from the page.
Next, the web crawler program produces a “weighted” index. A simple index is merely a list of words and the URL – not particularly good ay delivering useful search results.
Instead, the best web crawlers use various factors – such as the number of times a word is used throughout the document, whether the word appears in subheadings or if the word or phrase is actually in the title – to assign a weight to the word. Then, when a search is performed by a user, the most heavily weighted websites will appear at the top of the returned results.
You might wonder how searches across the vast Internet are accomplished so efficiently. The answer is with a technique known as hashing. The relevant search terms on a website are organized into “hash tables” which take the various ranked phrases and assigns them a number. This process significantly reduces the average time that it takes to do a search even if the search terms are somewhat complicated.
These days – although it is changing somewhat – most search engines perform a literal search. That is, they look for the phrases that a user enters into the query as exactly as possible. In addition, Boolean operators can be used quite effectively – if the user knows what they are doing – to narrow the search.
Newer search engine versions – not yet released – are currently being developed that will use natural-language and concept-based queries. The result will be search engines that deliver better results with less effort even if the user does not really know what they are doing.
Developing and generating interest in your website requires time effort and not a small degree of experience. Some business owners will find the lucky combination without the help of professional website developers. Most others, however, will fail. Do not make this mistake.
However, if you do not have a web developer on your team, you could always learn how to do it yourself. There are several ways to control web crawlers – through robots.txt file, meta robot tags, or through third-party solutions. In this article, we’re going to lay it all out and teach you how to do it through all 3 options.

To direct search engine crawlers with a robots.txt, first, you’ll need to create a robots.txt file.
The robots.txt file should be at the root of your website. For example, if your domain was example.com it should be found:
http://example.com/robots.txt/home/username/public_html/robots.txtWhen a search engine crawls a website, it requests the robots.txt file first and then follows the rules within.
You have a few ways of controlling how crawlers crawl your site with robots.txt file, you can either use:
The User-agent:
Disallow:
You can disallow any search engine from crawling your website with these rules:
User-agent: *</ul>
</li>
</ul>
<ul>Disallow: /Search engines are able to crawl your website by default, so adding this code is not necessary.
User-agent: *</ul>
</li>
</ul>
<ul>Disallow:If you have multiple directories such as /cgi-bin/, /private/, and /tmp/ that you didn’t want to be crawled, you could use the following code:
User-agent: *</ul>
</li>
</ul>
<ul>
<li style="list-style-type: none">
<ul>Disallow: /cgi-bin/</ul>
</li>
</ul>
<ul>
<li style="list-style-type: none">
<ul>Disallow: /print-ready/</ul>
</li>
</ul>
<ul>Disallow: /refresh.htmYou need to start a new line of “Disallow” for each URL you want to exclude.
If you only want to exclude a single crawler from access to your /private/ directory, and disallow all other bots you could use:
User-agent: Googlebot</ul>
</li>
</ul>
<ul>Disallow: /Instructions are given to Google only.
If we only wanted to allow Googlebot access to our /private/ directory, and disallow all other bots we could use:
User-agent: *</ul>
</li>
</ul>
<ul>
<li style="list-style-type: none">
<ul>Disallow: /</ul>
</li>
</ul>
<ul>
<li style="list-style-type: none">
<ul>User-agent: Googlebot</ul>
</li>
</ul>
<ul>Disallow:As you see, the rules of specificity apply, not inheritance.
Another way of controlling web crawlers if through Robots Meta Tag. You can use this method if you do not have access to the root directory, hence, can’t upload your robots.txt file. It is also great if you want to restrict web crawlers from crawling certain pages on your site.
The Robots Meta Tag is similar to other meta tags, and they are added in the <head> section of your code.
Examples of how Robot Meta Tags are used:
</ul>
</li>
</ul>
<ul>Even though the crawlers will not index the page, they will still follow links found on it.
</ul>
</li>
</ul>
<ul></ul>
</li>
</ul>
<ul>Most search engines cache your links for a certain period of time, which might bring visitors to the older version of your page. If your page is dynamic, you should use this tag so that search engines do not cache your page and will always bring visitors to the latest version of your page.
</ul>
</li>
</ul>
<ul>These commands instruct web crawlers to index the page and follow the links on it. They are unnecessary because the crawlers will do this by default.
Learning all these robots.txt or meta robot tags could be a lot of hassle for a small task, especially for people that doesn’t know how to code, doesn’t have access to the website’s backend, developers who are managing thousands of pages at the same time, etc.
However, what needs to be done has to be done, instructing crawlers what to do cannot be skipped. There aren’t many solutions available out there right now that could automate this process for you. Which is why we’ve included the “Robot Rules” function in our plugin.

With SEOPressor Connect, controlling web crawlers is as simple as a click.
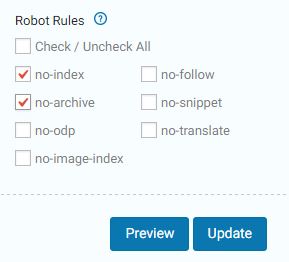
SEOPressor Connect allows you to control web crawlers with just a few ticks.
All you have to do is tick on the function you want, click update and SEOPressor Connect will generate the codes and inject them into your website. This function wasn’t available in SEOPressor v5 or the older versions of the plugin.
Along with many other features, they’re added into SEOPressor Connect so that you can have all the functions in one plugin. With SEOPressor Connect, you don’t have to install a ton of plugins, get your WordPress site cluttered, and worry about incompatibility issues. You can have all the On-Page SEO solutions in just one plugin – SEOPressor Connect.
Creating a diverse backlink profile can have a positive effect to your website, but how can you be sure that your efforts are working? By keeping track of your rankings.
We recommend using a tool like BiQ that has rank tracking function. Professional tools such as this will automatically refresh by itself every day, so you can have a day to day graph or your rankings.
![]()
Making it very easy for you to keep an eye on any changes that have happened.
So remember to keep track of your rankings so you can have a good idea on if your efforts are paying off and if you have set up your web crawler permissions properly.
Other articles you might like:
Updated: 14 July 2026

Struggling with internal linking?
Wish you could...

Automate internal linking
Use optimized anchor text
Fix 18 issues like orphan pages
Get link reporting and analytics


Save thousands of dollars (it’s 100x cheaper)
Zero risk of Google penalty (it’s Google-approved)
Boost your rankings (proven by case studies)
Rank High With This Link Strategy
Precise, Simplified, Fast Internal Linking.

Subscribe and receive exclusive insider tips and tricks on SEO.
Delivered to you right from the industry’s best SEO team.
Copyright © 2026 SEOPressor. All Rights Reserved.
Powered by Semantics BigData Analytics (SBDA).


{kind=link}