1
Steph W. from SEOPressor

👋 Hey there! Would you like to try out this New AI-Powered App that'll...
...help you check your website and tell you exactly how to rank higher?

Actionable SEO tips, tutorials, and insights to help you rank higher.
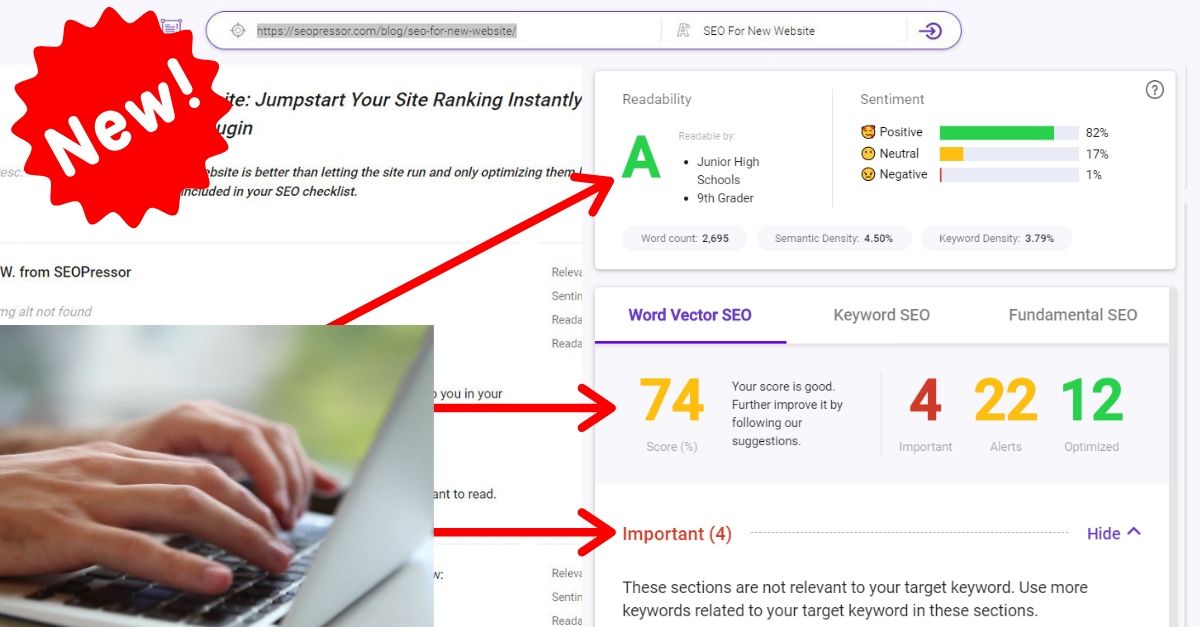
83
score %
SEO Score

Found us from search engine?
We rank high, you can too.
SEOPressor helps you to optimize your on-page SEO for higher & improved search ranking.
By jiathong on August 23, 2018

In SEO we always look at ranks and SERP, but we also need to know the process that happens before that. That is crawling and indexing.
Google ranks web pages that are in their index. If your web page is not indexed, or not correctly indexed, your rankings will be affected.
The web has moved from plain HTML – as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.
– John Mueller, Senior Webmaster Trends Analyst
The thing you need to know is this.
The process for JavaScript website and a non-JavaScript powered website is vastly different, and that’s why JavaScript is affecting your rankings if it’s not executed cautiously.
Google said in 2014 that they are trying to understand web pages better by executing JavaScript. But how do they actually do that? And to what extent can they render JavaScripts?
Let’s get a closer look at the whole crawling and indexing process.
Who, or in this case, what is involved in the process?
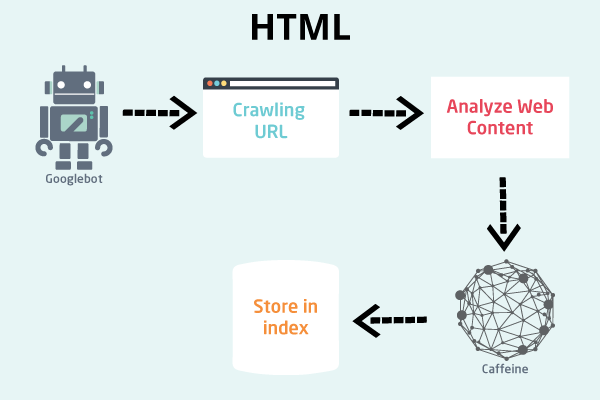
This is the crawler, also called the spider. Whenever there’s a new web page or any new updates on a webpage, Googlebot will be the first point of contact from the search engine.
What it does is it crawls the web pages and follows all the links in a web page. That way, the bot discover more new links and more new web pages to crawl. Crawled web pages are then passed to Caffeine for indexation.
Keep in mind that Googlebot CAN be denied access using robots.txt. The first thing to keep in mind if you want your JavaScript-powered web pages crawled and indexed is to remember to allow access for the crawlers. Remember to also submit your URLs to Google using the Google Search Console by submitting an XML sitemap.
The is the indexer that was launched in back in 2010. Whatever’s crawled by Googlebot will be indexed by Caffeine and that index is where Google choose which web pages to rank.
One important thing that Caffeine also does, other than indexing crawled contents is, Caffeine is also the one who renders JavaScript web pages. This is very important as for JavaScript, without rendering the search engine will not be able to index the complete content of a web page.
Links discovered from rendering will also be sent back to Googlebot to queue for crawling which will result in a second indexation. This is a very important point to keep in mind because one important part of SEO is internal linking. Inter-linking your web pages in your website gives Google a strong signal for things like page rank, authority and also crawl frequency. Which all, at the end of the day affects page ranking.
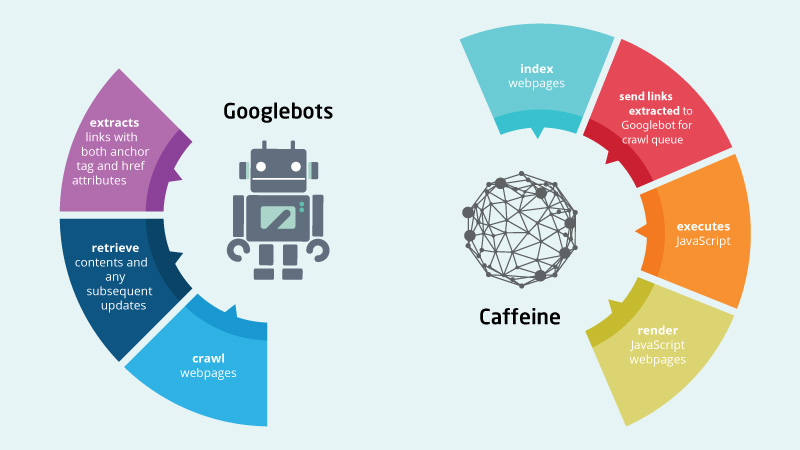
Here’s a quick image that sums up what Googlebot and Caffeine do.
Now making sure your site gets crawled and indexed is prerequisite of getting your site show up in the SERPs. One way to check your indexed paged is “site:yourdomain.com”, an advanced search operator.
Head to Google and type “site:yourdomain.com” into the search bar. Google will return results in its index for the site specified like this:
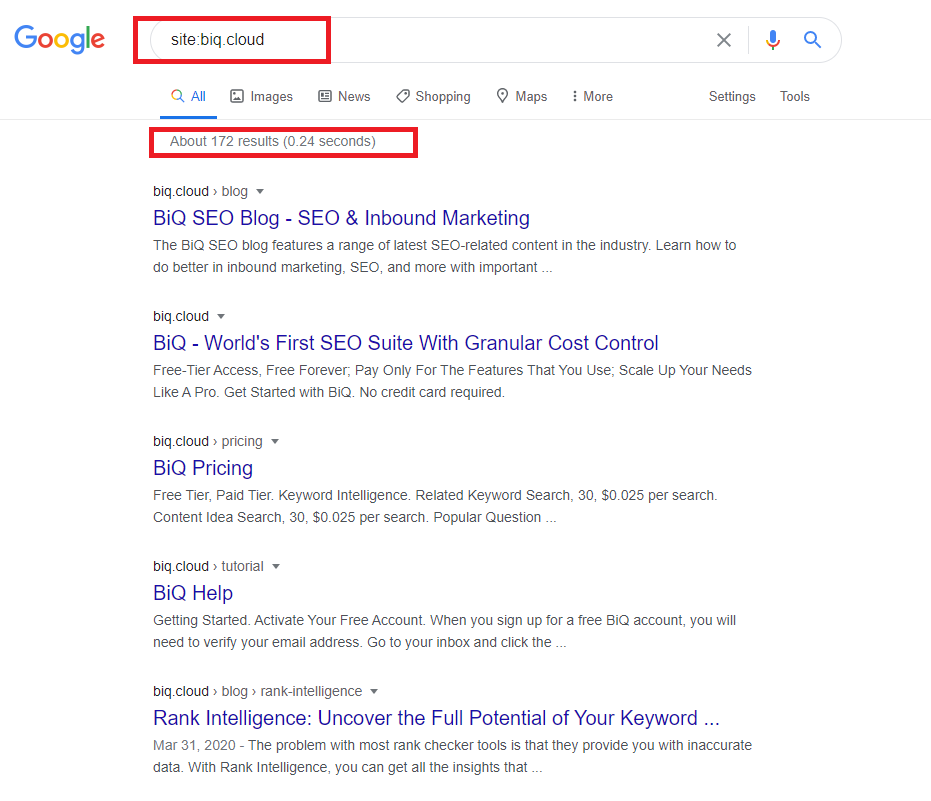
Here’s Google’s results of BiQ Cloud’s indexation, now go give your site a try!
The number of results Google displays (see “About XX results” above) isn’t exact, but it does give you a solid idea of which pages are indexed on your site and how they are currently showing up in search results.
For more accurate results, you can sign up for a free Google Search Console account if you don’t currently have one.
Here we have a straightforward graphic from this year’s Google i/o which shows you the flow from crawling to indexing and rendering.
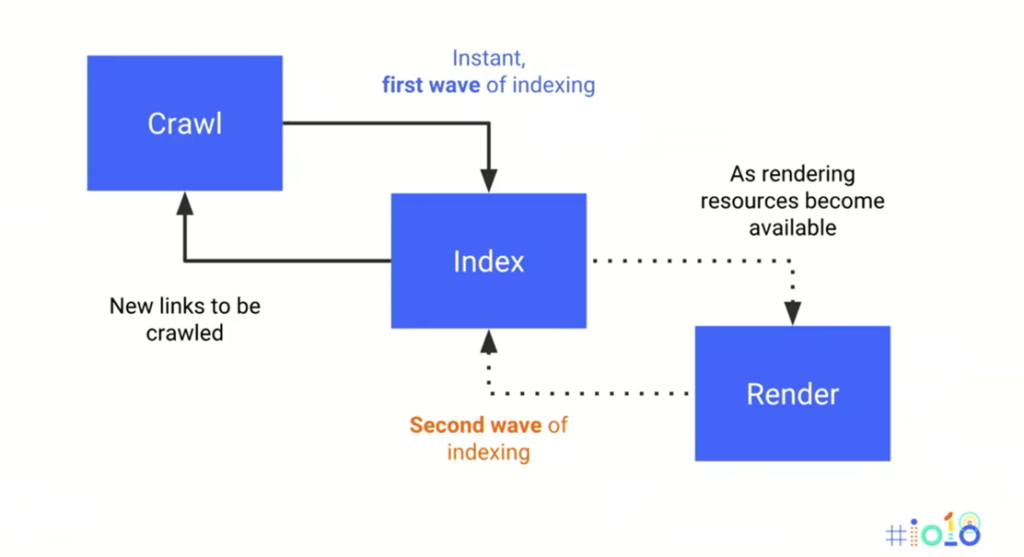
That is good for getting a general idea of the whole process, but why don’t we zoom a little closer?
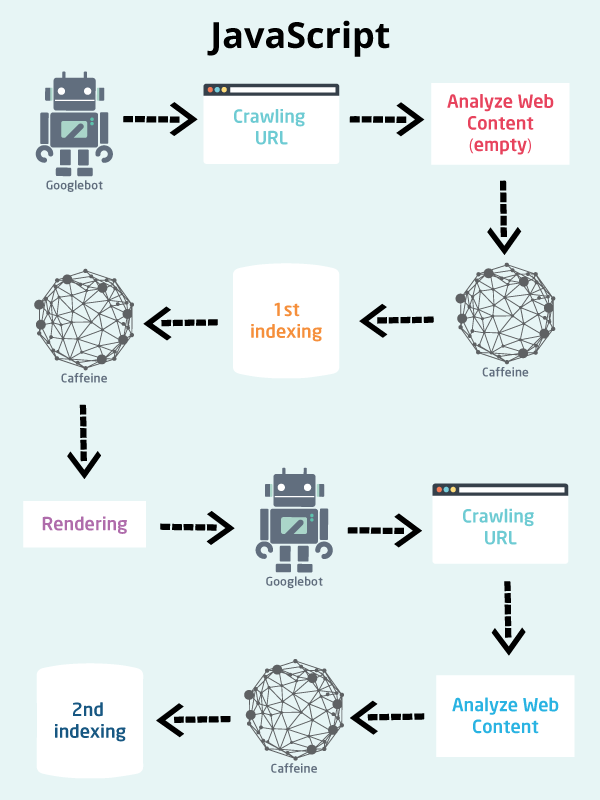
Well, that was the worst case scenario and what happens when you don’t implement your JavaScript in a way that can be rendered by the search engine.So the indexed version of your webpage is empty, as far as Google’s concern.
Now, empty web pages will not rank well. Which is why, you need to understand how to implement your JavaScript in a way where it will be indexed completely, or as close as it could be to how it appears to a user using a modern browser.
Fortunately, now Caffeine actually has the ability to render your JavaScript files like a browser would. Google gave all the SEO and web developers a big surprise when they revealed that the search engine’s WRS(Web Rendering Service) is actually based on Chrome 41. With the Chrome 69 rolling out in September, the search engine is grossly underpowered in terms of rendering modern JavaScript. But hey, that’s better than nothing right?
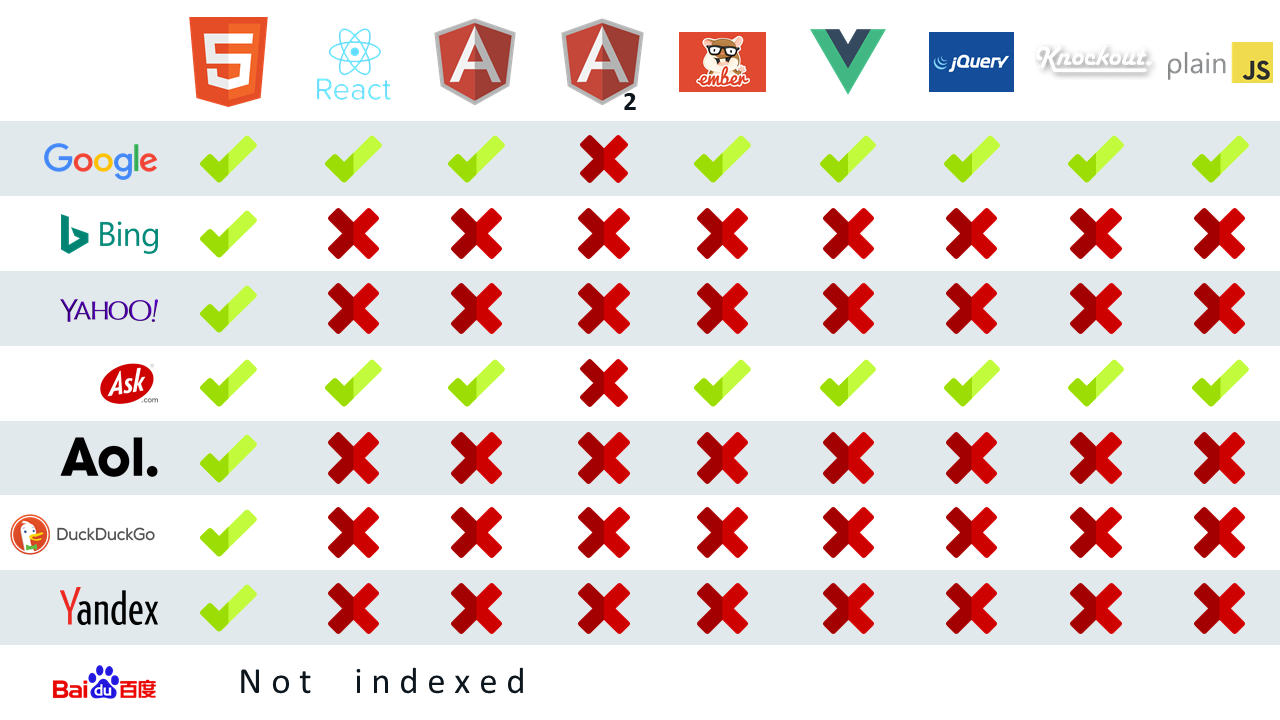
Google currently leads the race of which search engine can index your JavaScript web pages better. (ps: ask.com gets a part of their indexation from an unnamed third party search engine, I guess we all know who that is…)
So does this mean Google can crawl and index your JavaScript-powered web pages with no problem? Well, the short answer is no. I mean, look at Hulu.
Google can crawl JavaScript, but not all JavaScript. That’s why it is so important to implement graceful degradation to your webpages. That way, even when the search engine can’t render your web pages properly, at least it won’t be catastrophic (think Hulu).
The thing for Google with crawling JavaScript is, it is resource heavy and expensive. The first indexation can happen as quickly as they can index an HTML side, but the important part, the second indexation post rendering will be put on the queue until they have free resources to do so.
Which means, imagine this, you served Google a meal, but because they don’t have the cutlery to eat it, they can only judge how good it is by looking, and the server won’t be back with the cutlery until they’re done taking orders from 3 more other tables, Google then post a review on Yelp saying that your food is crap.
Does that sound fair and beneficial? Hell no.
Like crawl rate, how fast and frequent the second indexation will go depends on several factors like page rank, backlinks, update frequency, visitor volume and even the speed of your website.
So how can you make sure that Google can crawl, render and index your JavaScript website correctly? Note, not quickly, because that is a whole other question to answer.
Two important tools you can used to gauge how good can Google crawl and index your JavaScript website is by using the Fetch and Render Tool from Google Search Console and the Chrome 41 browser (you can download the browser here, shout out to Elephate and their awesome post on Chrome 41 and rendering)
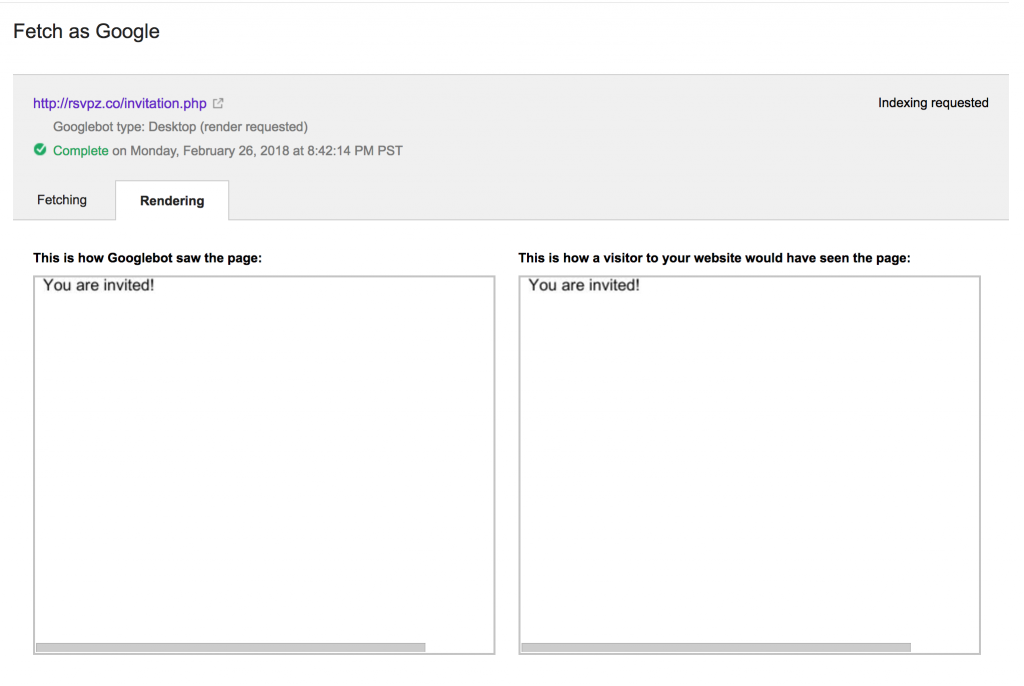
Use the fetch as Google function to check whether the search engine can properly render your web page or not. (source)
You can also go to CanIUse to check out what is and is not supported by Chrome 41.
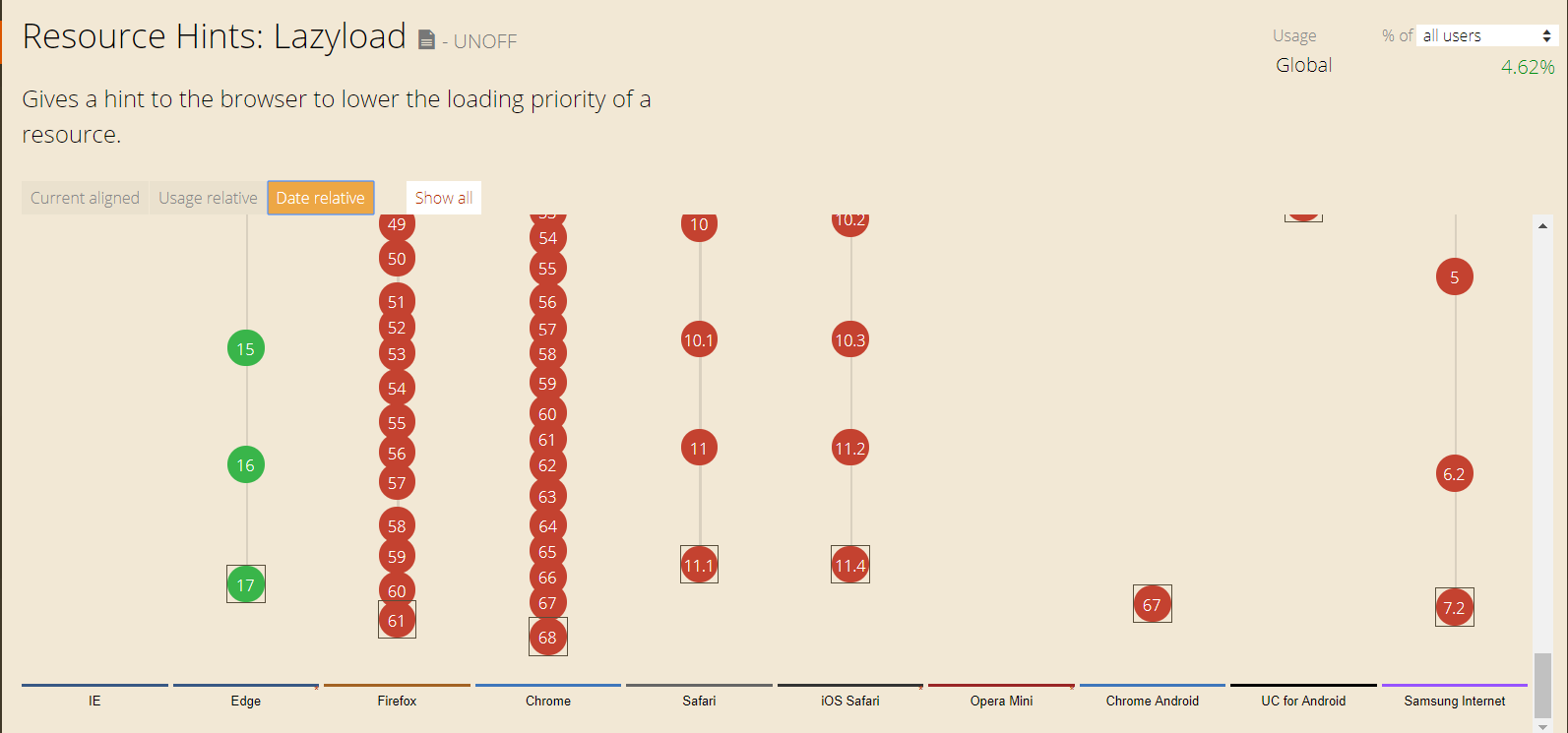
The website gives you a clear view of what is and is not supported by all browser versions. Use this to double check whether your script can be executed by Chrome 41, thus rendered by Caffeine.
These are all crucial tools that help you understand the whole crawling, rendering, and indexing process. With that, you’ll have a better idea of where and what went wrong.
Then you’ll be losing all opportunities (rank, traffic, leads) to your competitors. You’ll need to have what we call a Rank Intelligence tool to get things working on your side.
Rank Intelligence by BiQ SEO Suite that allows you to leverage data for site analysis and uncover opportunities that’ll allow expansion and control of your search landscape.
The best part of this feature is enabling you to discover rankings that you don’t even know you stand a chance for!
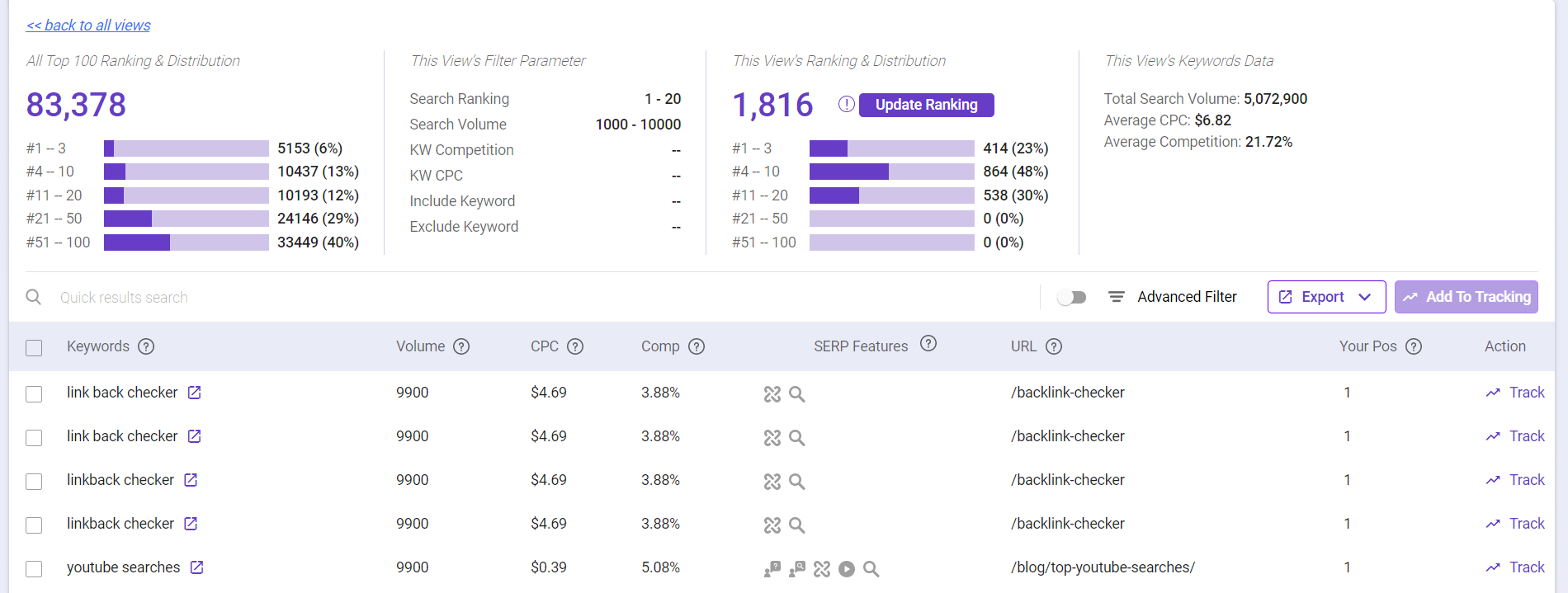
Imagine having over 100+ websites over the years and each of them are left aside without proper care to get it ranked once high. Knowing the right keyword and its position in the SERP will give you a chance to revive your websites for the better!
Better still, BiQ has a Rank Tracking that helps you big time when it comes to tracking and monitoring all your sites once you’re done with optimizing your sites. Talk about efficiency!
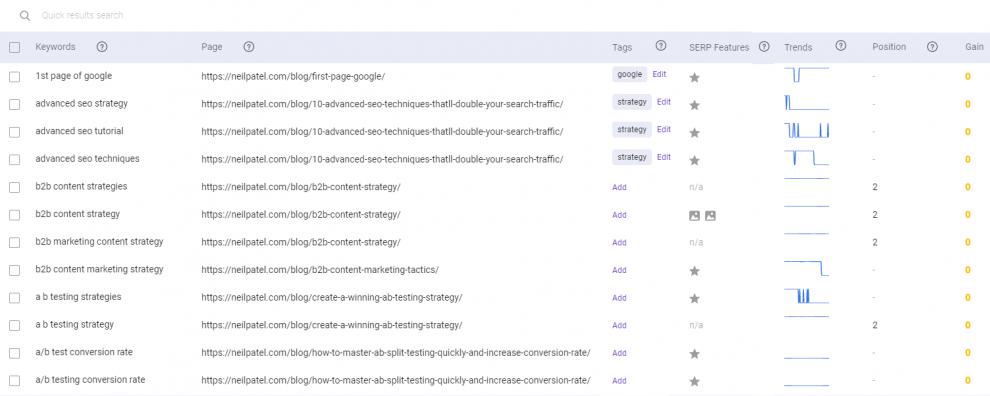
These vital information in Rank Intelligence (& Rank Tracking) will provide real-time exploration at your fingertips to unleash the power of your ranking website – exclusive to BiQ Cloud, with the speed of thought.
1. Googlebot crawls, Caffeine index and render.
2. For HTML web pages, Googlebot requests a page and downloads the HTML, contents are then indexed by Caffeine.
3. For JavaScript web pages, Googlebot request a page, downloads the HTML, first indexing happens. Caffeine then renders the page, send rendered links and data back to Googlebot for crawl queue, after re-crawl, cue second indexation.
4. Rendering is resource heavy and second indexation will be put on queue, which makes it less efficient.
5. Use the fetch and render tool on Google Search Console and Chrome 41 to gauge how good can Google index your JavaScript page.
6. Make sure your efforts does not go to waste by making sure your website is also ranked for the right keywords using BiQ”s Rank Intelligence.
Here is another post on JavaScript SEO that may interest you: SEO for JavaScript-powered websites (Google IO 18 summary)
Updated: 25 July 2026

Subscribe and receive exclusive insider tips and tricks on SEO.
Delivered to you right from the industry’s best SEO team.
Copyright © 2026 SEOPressor. All Rights Reserved.
Powered by Semantics BigData Analytics (SBDA).

{kind=link}