1
Steph W. from SEOPressor

👋 Hey there! Would you like to try out this New AI-Powered App that'll...
...help you check your website and tell you exactly how to rank higher?

Actionable SEO tips, tutorials, and insights to help you rank higher.
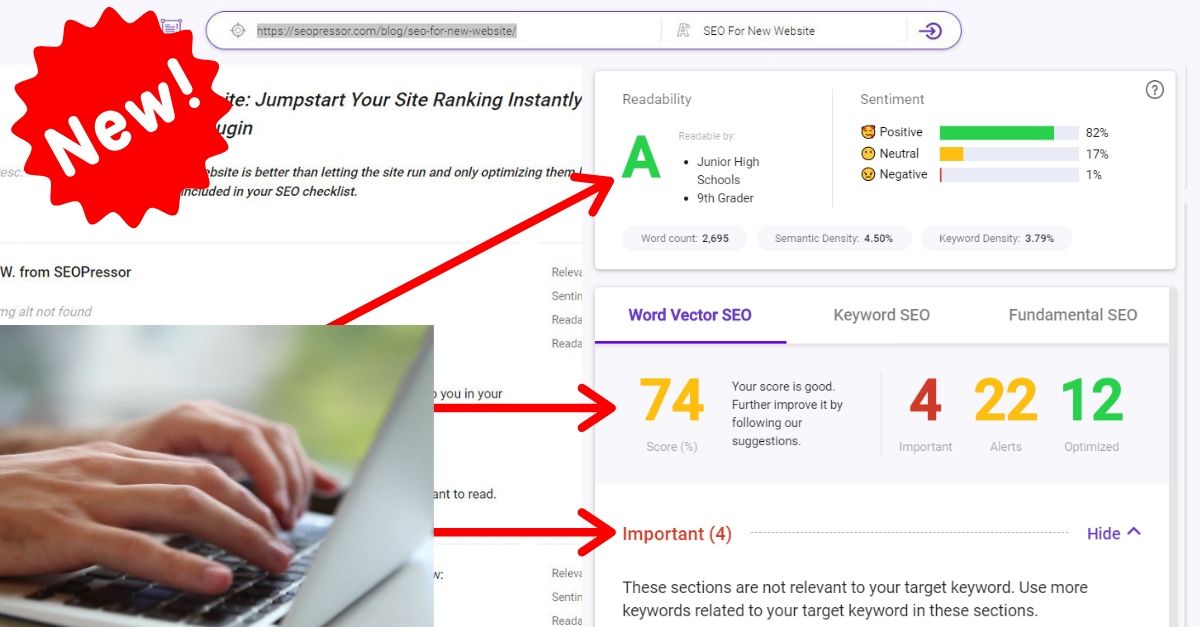
90
score %
SEO Score

Found us from search engine?
We rank high, you can too.
SEOPressor helps you to optimize your on-page SEO for higher & improved search ranking.
By jiathong on May 28, 2018

You have probably heard that in the recent Google I/O 18, Google shed some light on SEO.
Tom Greenaway and John Muller of Google presented a session about making your modern JavaScript powered websites search friendly.
They actually listed some recommended best practices, useful tools, and Google policy change.
Here’s the thing:
In a pretty un-Google like way, the duo also shed some light on how the actual crawl and index process for javascript websites work.
Check out the video here:
But, if you don’t want to spend 40 minutes watching the recording.
Hang around, cause here’s a quick summary of the important key points of the session.
Tom Greenaway is a senior developer advocate from Australia. While John Mueller (aka johnmu, ring a bell?), is Google’s webmaster trends analyst from Zurich, Switzerland.

Tom started the talk by sharing a little background of search engines.
Here’s the deal,
The purpose of search engines is to provide a relevant list to answer user’s queries. A library of web pages is compiled where answers are pulled from.
That library is the index.
Building an index starts with a crawlable URL.
Now, the crawler is designed to find contents to crawl.
But, in order to do this, the content must be retrievable via an URL. When the crawler gets to an URL, it will look through the HTML to index the page as well as find new links to crawl.
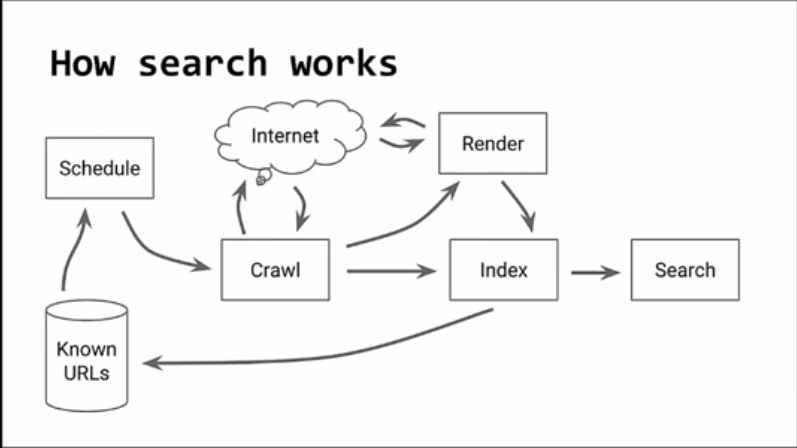
Here’s a diagram on how search works for Google.
Here’s what you need to know, Tom shared the six steps to ensure your web page will be indexed.
– Set up robots.txt at the top level domain of your site. Robots.txt is useful to let Googlebot know which URLs to crawl and which to ignore.
– In case of content syndication where a content is distributed on different sites to maximize exposure. The source document should be tagged as the canonical document.
– Don’t list session information on the URL.
– That way the crawler has a list of URLs to crawl and you can sleep better at night knowing your website is properly crawled.
– It replaces the hashbang tag(#!), which, if used will no longer be indexed.
– Googlebot only recognizes links with BOTH anchor tags and HREF attributes, otherwise, they won’t be crawled therefore never indexed.
What’s more important is,
Tom said Google has been encountering a list of problems trying to crawl and index websites that are built using Javascript.
Here’s the list of most commonly face problem for javascript website indexing
Make sure to have a good look at it, don’t wanna be repeating these same mistakes.
– Which leads Googlebot to assume that there’s nothing to index.
– Make sure that they are properly indexed,use noscript tag or structured data.
– Take caution, images only referenced through CSS are not indexed.
-Googlebot is not an interactive bot, which means he won’t go around clicking tabs on your website. Make sure the bot can get to all your stuff by either preloading the content or CSS toggling visibility on and off.
– What’s better, just use separate URLs to navigate user and Googlebot to those pages individually.
– Make sure your page is efficient and performant by limiting the number of embedded resources and avoid artificial delays such as time interstitials.
– What happens instead is that Googlebot crawls and renders your page in a stateless way.
Now, due to the increasingly widespread use of JavaScript, there is another step added between crawling and indexing. That is rendering.
Rendering is the construction of the HTML itself.
Like mentioned before, the crawler needs to sift through your HTML in order to index your page. JavaScript-powered websites need to be rendered before it can be indexed.
According to Tom and John, Googlebot is already rendering your JavaScript websites.
-Chrome 41 is from 2015 and any API added after Chrome 41 is not supported.
– Rendering web pages is a resource heavy process, therefore rendering might be delayed for a few days until Google has free resources.
– First indexing happens before the rendering process is complete. After final render arrives there will be a second indexing.
– The second indexing doesn’t check for canonical tag so the initially rendered version needs to include the canonical link, or else Googlebot will miss it altogether.
– Due to the nature of two-phase indexing, the indexability, metadata, canonical tags and HTTP codes of your web pages could be affected.

John Mueller takes the baton and shares with us some basic information on rendering.
What’s important is, he shared with the crowd which is the preferred rendering method of Google.
2. Server side rendering
– Your server deals with the rendering and serve users and search engine alike static HTML.
3. Hybrid rendering (the long-term recommendation)
– Pre-rendered HTML is sent to users and search engine. Then, the server adds JavaScript on top of that. For the search engine, they will simply pick up the pre-rendered HTML content.
4. Dynamic rendering (the policy change & Google’s preferred way)
– This method sends client side rendered contents to users while search engines got server side rendered content.
– This works in the way that your site dynamically detects whether its a search engine crawler request.
– Device focused contents need to be served accordingly (desktop version for the desktop crawler and mobile version for the mobile crawler).
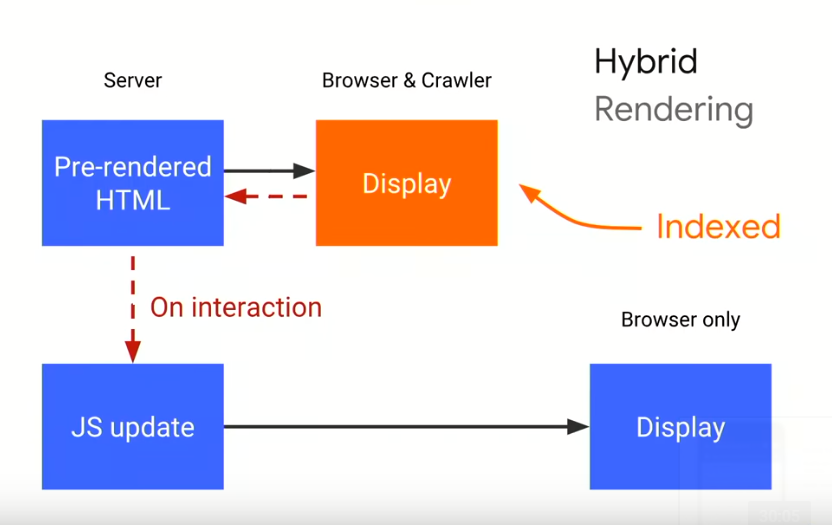
How hybrid rendering works.
Now that it is out in the open that Google prefers the (NEW) dynamic rendering method to help the crawling, rendering and indexing of your site. John also gives a few suggestions on how to implement dynamic rendering.
2. Rendertron
– Could be run as a software or a service that renders and caches your content on your side.
Both of these are open source projects where customization is abundant.
John also advises that rendering is resource extensive, so do it out of band from your normal web server and implement caching where needed.
The most important key point of dynamic rendering is this,
it has the ability to recognize a search engine request from a normal user request.
But how could you recognize a Googlebot request?
John stresses during the session that implementing the suggested rendering methods is not a requirement for indexing.
What it does, is it makes the process crawling and indexing process easier for Googlebot.
Considering the resource needed to run server side rendering, you might want to consider the toll before implementing.

Here’s what,
When you have a large and constantly updated website like a news portal because you want to be indexed quickly and correctly.
Or, when you’re relying on a lot of modern JavaScript functionality that is not supported by Chrome 41, which means Googlebot won’t be able to render them correctly.
And finally, if your site relies on social media or chat applications that require access to your page’s content.
Now let’s look at when you don’t need to use dynamic rendering.
The answer is simple,
if Googlebot can index your pages correctly, you don’t need to implement anything.
So how can you know whether Googlebot is doing their job correctly?
You can employ a progressive checking.
Keep in mind that you don’t need to run tests on every single web pages. Test perhaps two each from a template, just to make sure they are working fine.
2. Run a Google Mobile Friendly Test.
Why?
Because of the mobile-first indexing that is being rolled out by Google where mobile pages will be the primary focus of indexing. If the pages render well in the test, it means Googlebot can render your page for Search
3. Keep an eye out for the new function in the mobile friendly test. It shows you the Googlebot rendered version and full information on landing issue in case it doesn’t render properly.
4. You can always check the developer console when your page fails in a browser. In developer console, you can access the console log when Googlebot tries to render something. Which allows you to check for a bunch of issues.
5. All the diagnostics can also be run in the rich results test for desktop version sites.

At the end of the session, John also mentions some changes that will happen.
The first happy news,
Google will be moving rendering closer to crawling and indexing.
Which we can safely assume that it will mean that the second indexing will happen much quicker than before.
The second happy news,
Google will make Googlebot use a more modern version of Chrome. Which means a wider support of APIs.
They do make it clear that these changes will not happen until at least the end of the year.
To make things easier, here are the four steps to make sure your JavaScript-powered website is search friendly.

With that, the session is concluded. Do check out our slide show for a quick refresh.
All in all, Google is taking the mic and telling you exactly what they want.
Better take some note.
Updated: 27 July 2026

Subscribe and receive exclusive insider tips and tricks on SEO.
Delivered to you right from the industry’s best SEO team.
Copyright © 2026 SEOPressor. All Rights Reserved.
Powered by Semantics BigData Analytics (SBDA).

{kind=link}