1
Steph W. from SEOPressor

👋 Hey there! Would you like to try out this New AI-Powered App that'll...
...help you check your website and tell you exactly how to rank higher?

Actionable SEO tips, tutorials, and insights to help you rank higher.
93
score %
SEO Score

Found us from search engine?
We rank high, you can too.
SEOPressor helps you to optimize your on-page SEO for higher & improved search ranking.
By jiathong on July 21, 2020

Did you know that you have more power over search engines now more than ever?! Yes, that’s true, now you can control who crawls or indexes your website using robots.txt.
It is a plain txt file within the root directory of your site that tells crawlers whether to access or overlook certain pages, folders, along with other data on your website. It utilizes the Robots Exclusion Standard protocol designed in 1994 for sites to engage with bots ad crawlers.
Now, this is a vital tool that you can use to display your site to search engines in a way that you want them to view it.
At a fundamental level, search engine especially Google are usually very harsh and strict judges of character, so you must make a good impression if you want to stand out.
And when used properly, robots.txt can help you achieve that through enhancing crawl frequency, which in turn will positively affect your SEO efforts.
A few decades back, when the World Wide Web was still in diapers, site developers designed a way for bots to crawl and index new pages online.
The bots were known as ‘spiders.’
Sporadically, the spiders would deviate onto sites that were not intended to be indexed or crawled, such as websites that are undergoing maintenance.
It is because of such issues that developers came up with a solution that created a road map for all bots in 1994. The protocol sketches out rules that every genuine robots must adhere to, including Google bots.
Illegitimate bots like spyware, malware, and others operate outside this protocol.
To check the robots.txt of any site, type the URL and add “/robots.txt” at the end.
Robots.txt is not a must-have for every website, particularly small or new ones. However, there is no viable reason not to have the file as it gives you more power over where different search engines can and cannot go on your site, and this can help;
The file must be saved as ASCII or UTF-8 in your web page’s root directory. The name of the file should be unique and contain one or more rules crafted in a readable format. The rules are structured from the top to the bottom where the lower case and upper case letters are differentiated.
Terms used
Now, the instructions in the file usually contain two parts. The first section is where you denote which robots the instruction applies to. The second section, entail the allow or disallow instruction.
For example. “User-agent; BingBot” plus the instruction “allow: /clients/” means that BingBot is allowed to search the /clients/ directory.
For instance, the robots.txt file for the site https://www.bot.com/ could look like this:
User-agent: *
Allow: /login/
Disallow: /card/
Allow: /fotos/
Disallow: /temp/
Disallow: /search/
Asallow: /*.pdf$
Sitemap: https://www.bot.com/sitemap.xml
Setting up the file is not as difficult as you think. Just open any blank document and start typing instructions. For instance, if you want to allow search engines to crawl your admin directory, it would look like this:
User-agent: *
Disallow: /admin/
You can continue doing so until you are okay with what you see and then save the directives as “robots.txt.” There are also tools that you can use to do so. One main advantage of using reliable tools is that you minimize syntax errors.
And this is very crucial because a simple mistake can result in an SEO meltdown for your website. The downside is that they are somehow limited when it comes to customizability.
As mentioned earlier, robots txt control how various search engines access your website. It has instructions that direct search engines which pages to access and which ones not to access.

While it is a beneficial tool when used properly, it can also affect your site adversely when used wrongly.
Here are instances when NOT to use your robot.txt for;
Search engines must access all the resources on your websites to properly render pages, which is vital for maintaining good rankings. Disallowing crawlers from accessing JavaScript files that alter user experience may result in algorithmic or manual penalties.
For instance, if you redirect your site visitors with a JavaScript file that search engines cannot access may be regarded as cloaking, and your site ranking may be adjusted downwards.
Blocking URLs within the file hinders link equity from going through to the site. This essentially means that if Google is unable to follow a link from another site, your website will not acquire the authority that the links are offering and as such, you may not rank well in general
If you want to rank well, you must allow social networks to access some pages of your site to develop a snippet. For instance, if you post your site’s URL on Facebook, it will try and visit every page to have a useful snippet. So don’t give directions that disallow social networks from accessing your website.
This is not acceptable
User-agent: *
Allow: /
Or like this:
User-agent: *
Disallow:
Disallowing your site entirely is not good for your site; your site will not be indexed by search engines meaning your ranking will be affected. Similarly, leaving your website unprotecting by allowing access to everything is not good.
Besides, there is no need to have such a directive unless you are operating a static 4-page site with nothing essential to hide on the server.
Misdirecting search engines is a terrible idea.
If your website’s sitemap.xml has URLs that are explicitly blocked by robots.txt, you are misleading yourself. This mostly happens if the file and sitemap files are developed by different tools and not checked afterward.
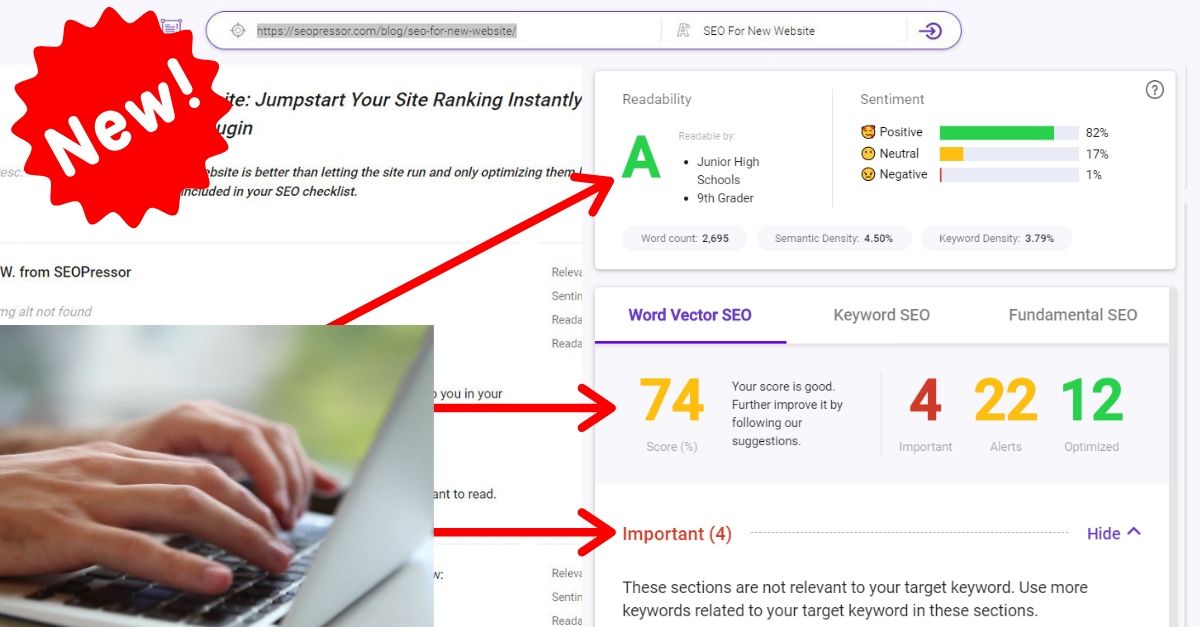
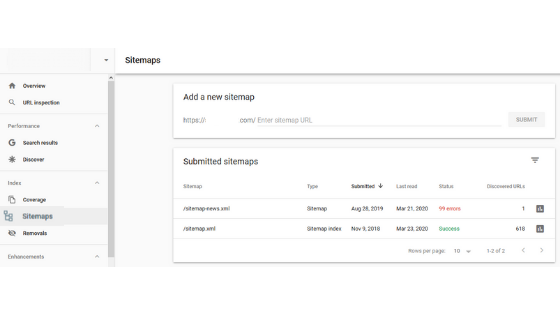
To check if your site has this problem, head to Google Search Console. Add your site, verify it, and submit an XML sitemap for it. You will see on sitemaps under the Index tab.
We recommend using robots.txt rules only for crawl efficiency issues or server problems such as bots spending time crawling non-indexable sections of your site. Some pages that you may not want bots to crawl on include;
Robots.txt has a substantial impact on SEO as it allows you to manage search bots.
However, if the user agents are restricted extensively by dis-allow directives, they may have a negative influence on your site’s ranking. Also, you will not rank with pages that you have disallowed crawling and indexing.
On the other hand, if there are very few disallow directives, duplicate pages may be indexed, which can have a negative on the pages’ ranking.
Also, before saving the file in your site’s directory, confirm the Syntax.
Even minimal errors can result in bots disregarding your allow or disallow instructions.
Such mistakes can result in the crawling of sites that should not be indexed as well as pages to be inaccessible for bots because of disallowing. Google Search Console can help you confirm the correctness of your file.
That said, using the robots.txt appropriately will ensure all the essential sections of your site are crawled by search bots, consequently indexing your content by Google and other relevant search engines.
WordPress, by default, creates virtual robots.
So without doing anything on your site, it should have the file. You can confirm this by appending “/robots.txt” to the end of your site’s domain name.
For instance, “https://google.com/robots.txt” brings up the robots.txt file that the platform uses. Now because it is a virtual file, you cannot edit it. If you must edit it, you will have to create a physical file on your server.
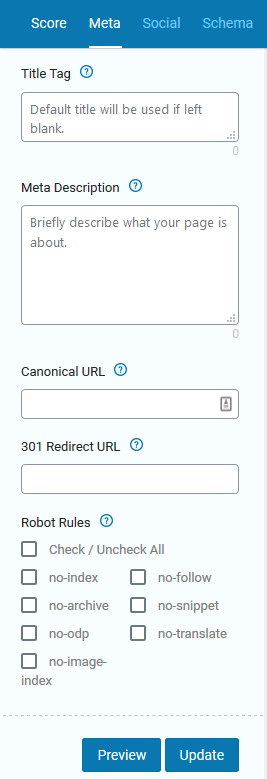
Here is a simple way to control your robots.txt with SEOPressor:
You can manually select what to disallow for each new post you create under the meta tab of SEOpressor.
This is really easy and beginner-friendly, all you need to do is tick a few boxes and you are done!

In a flawless society, robots.txt would be of no use. If all the parts of a site were designed for the public, then technically, Google and other search engines would be allowed access to all of them.
Unfortunately, the world is not perfect. Many websites have non-public pages, canonical URL issues, and spider traps that must be kept out of Google. That’s where robots.txt files come in handy to move your website closer to splendid.
Also, robots.txt is amazing for search engine optimization. It makes it easy to instruct Google on what to index and what not to. Be as it may, it must be handled cautiously because one bad configuration can easily result in the DE-indexation of your site.
Updated: 27 July 2026

Subscribe and receive exclusive insider tips and tricks on SEO.
Delivered to you right from the industry’s best SEO team.
Copyright © 2026 SEOPressor. All Rights Reserved.
Powered by Semantics BigData Analytics (SBDA).

{kind=link}